Designing for Color blindness
Color choices and transformations for deuteranopia and other afflictions
Here, I help you understand color blindness and describe a process by which you can make good color choices when designing for accessibility.
The opposite of color blindness is seeing all the colors and I can help you find 1,000 (or more) maximally distinct colors.
You can also delve into the mathematics behind the color blindness simulations and learn about copunctal points (the invisible color!) and lines of confusion.
Maximally distinct colors
contents
Color blindness is the inability to distinguish colors. The converse of this is a set of maximual distinct colors — interesting in its own right and subject of this section.
Below I also provide helpful diagrams that visualize how color differences vary. These show the difference between two modern formulae for color differences: `\Delta E_{94}` and `\Delta E_{00}`.
When we had reached 3 petabases milestone in our sequencing, I made a graphic of a DNA double helix of 3,000 base pairs that wound into the shape of "3Pb". I wanted to color each base on a strand with a different reasonably saturated and bright color — the base on the opposite strand would be its RGB inverse.
I didn't want just different — I wanted maximally distinct. While it's very easy to pick any number of RGB colors that are different, it's trickier to make sure that they're all as different from each other as possible.
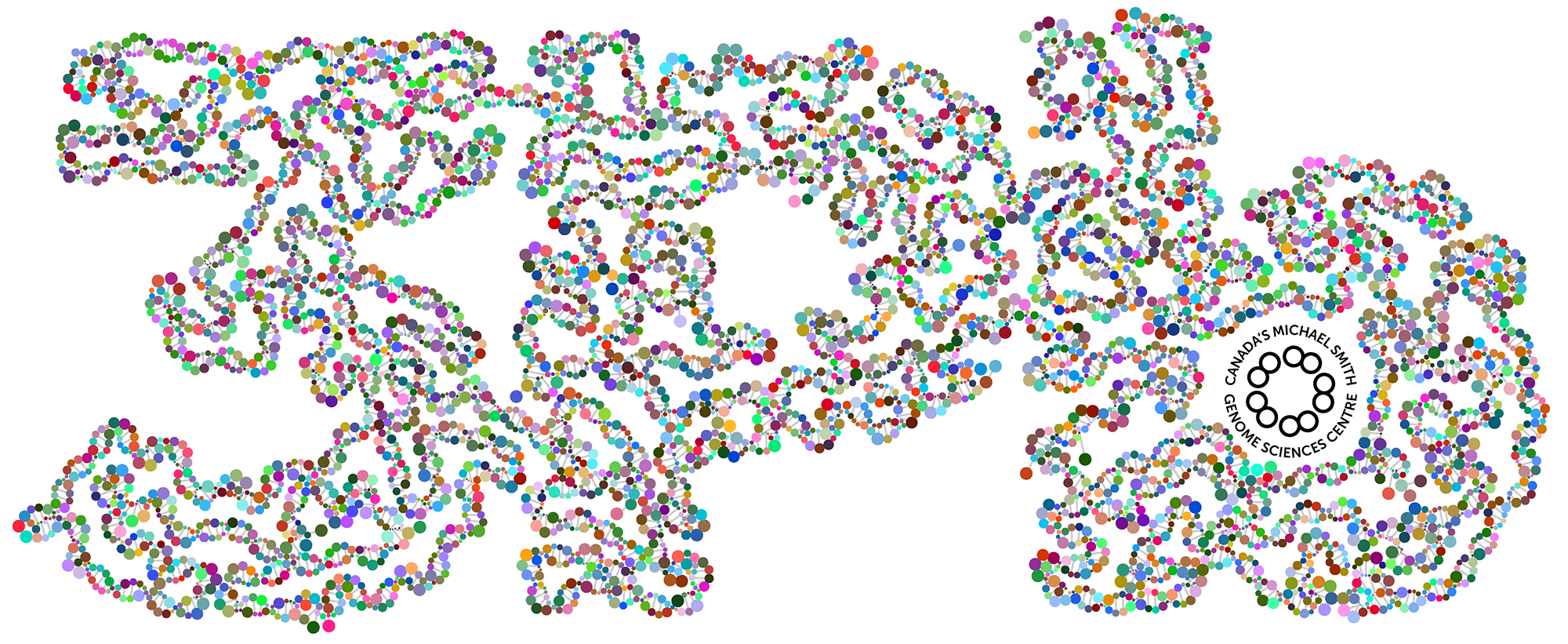
Here, I outline a method for selecting such a large number of distinct colors and provide these color sets for you to download. You can pick anywhere a set of anywhere from `N=20` to `5,000` maximally distinct colors.
The selection method described below is essentially the same as offered by the excellent iwanthue project, which provides an excellent visual tutorial of the idea of color differences. Unfortunately, the tool timed out when attempting to find 3,000 different colors, so I thought I'd generate a set myself.
These sets are from a subset of the 815,267 colors (see methods) limited to `L = 20-80` and `C \ge 20`. Extremely bright colors (e.g. pure yellows) are not included. For sets drawn from the full complement of 815,267 colors, see below.
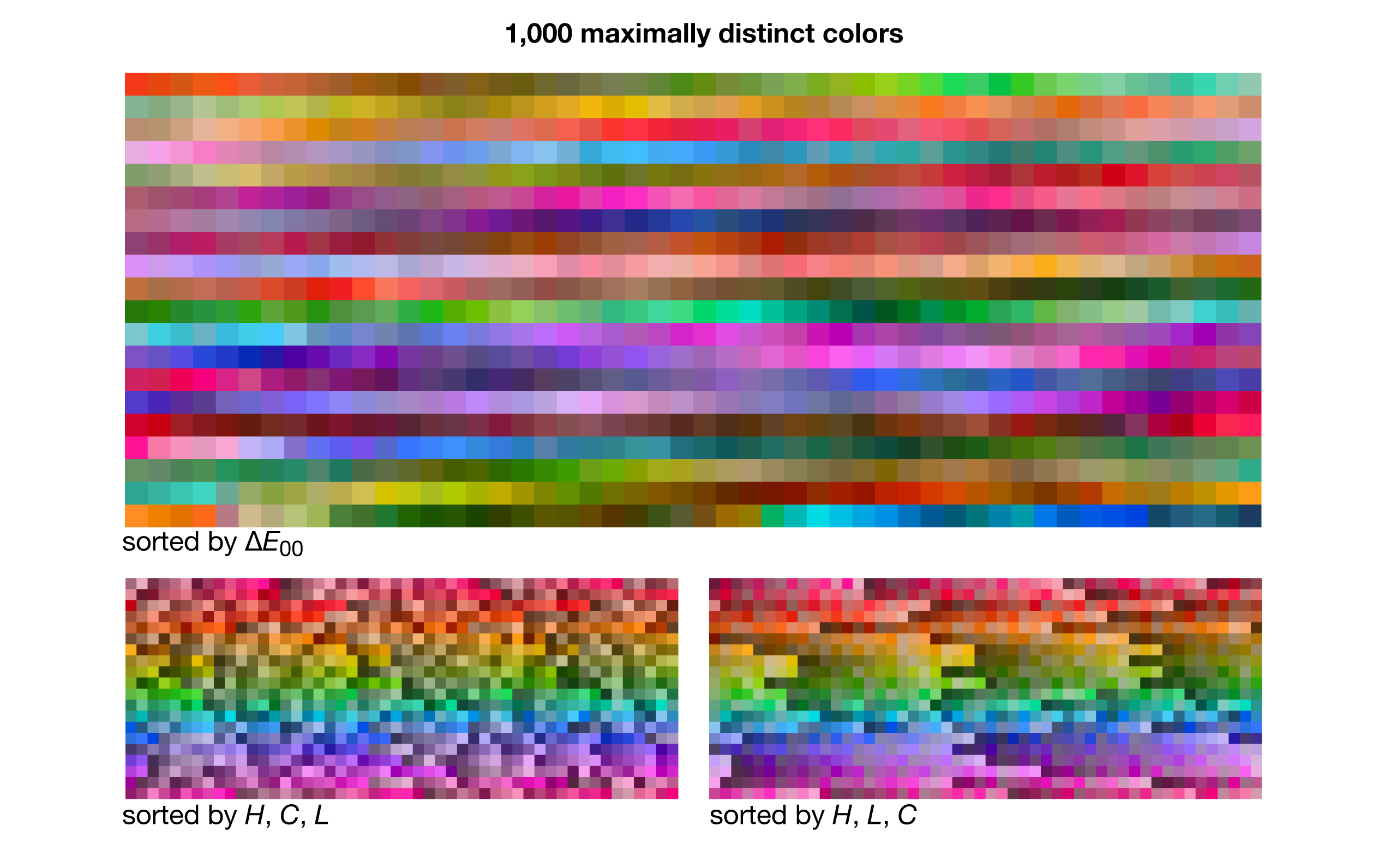
Shown below are sets of `N=5-50` maximally distinct colors. The first swatch in the set is the one closest to pure RGB red (255,0,0). The next swatch is the first swatche's closest `\Delta E` neighbour and so on — the order is sensitive to small changes in color difference as well as the color of the first patch so it can be quite different for each set. The average `\Delta E` between closest neighbours is shown on the left — the fewer the colors, the larger the color clusters from which they were sampled and thus the larger the `\Delta E`.
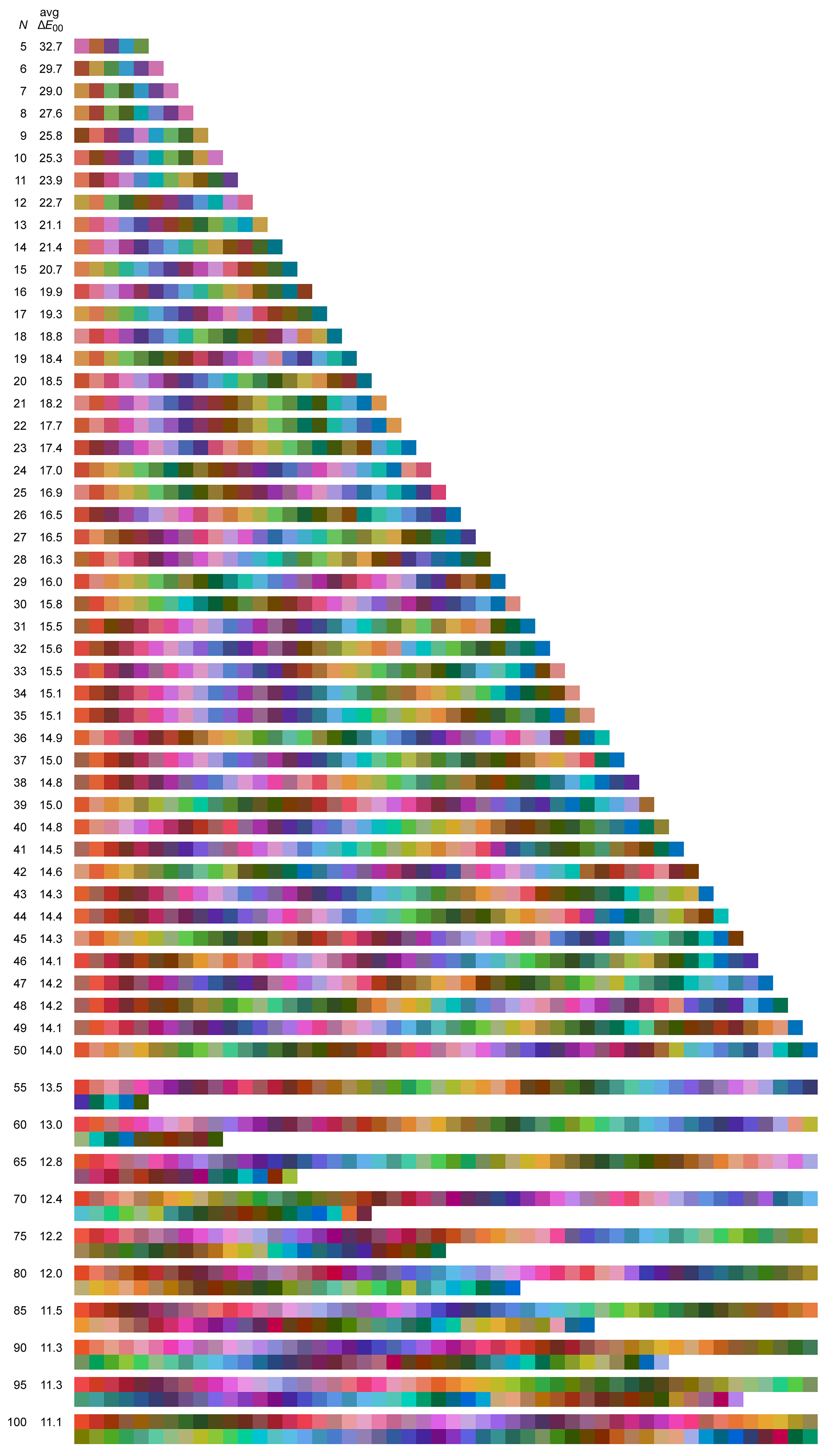
The k-means clustering is stochastic — each time it's run you get a slightly different result as the algorithm tries to search for a global maximum (it won't find it but it will find many local minima).
Some larger sets of maximally distinct colors are shown below, ordered by either `\Delta E` or LCH.

The benefit of sorting by closest neighbours is that you can see the extent to which the color space is sampled — as the set of colors grows, a color's nearest neighbour becomes more and more similar. Sorting by LCH (hue first, then chroma, then luminance — each rounded off to nearest 5) helps to see how many colors from a given part of the hue wheel are chosen. For example, note how there's generally more reds than blues.
A more in-depth description of color differences is below. For the color selection I use CIE00 (`\Delta E_{00}`) but CIE94 would probably be just as good (and faster).
The process of selecting this set of maximally distinct colors starts with sampling all LCH colors in the range `LCH = [0,100] \times [0,100] \times [0,359]` in steps of `0.5` in each dimension. This creates an initial set of 28.8 million colors — more than 24-bit RGB colors. So, too many!
First, I eliminate all colors that have identical integer RGB values. This leaves me with 6.1 million colors.
Then, to make the analysis more practical, I find a subset of the 6.1 million by eliminating any colors that already have a color within `\Delta E_{00} < 0.5` in the set. Remember that neither Lab (and therefore LCH aren't perceptually uniform) so among the 6.1 million colors, some will be more similar to each other than others.
This filtering gives me 815,267 RGB colors (download list). In this set, the average distance between nearest color neighbours (`\Delta E`) is 0.54 and 99% of the `\Delta E < 0.8`. Only 683 (<0.1%) of colors have a nearest neighbour with `\Delta E > 1` and 41 colors have a nearest neighbour with `\Delta E > 2`. These are in areas where `\Delta E` changes quickly with small changes in RGB. For example the two colors (46,0,0) and (47,0,0) have a `\Delta E = 2.0` but only vary by `\Delta R = 1`.
I'm sticking to integer RGB values — given that I'm sampling a very large number of colors, the few places where carrying a decimal would even out the local sampling is negligible. As well, my original purpose of creating these color sets was for design and most applications (Photoshop, Illustrator, etc) limit you to integer RGB.
To find the set of `N` maximally distinct colors, I apply k-means clustering using `\Delta E_{00}` as the distance metric. For sets `N = 5-100` I run k-means 100 times and choose the one with lowest error. For `N=110-200` I run k-means 25 times and for `N=225-1000` I run it 5 times. For `N>1000` I run k-means only once.
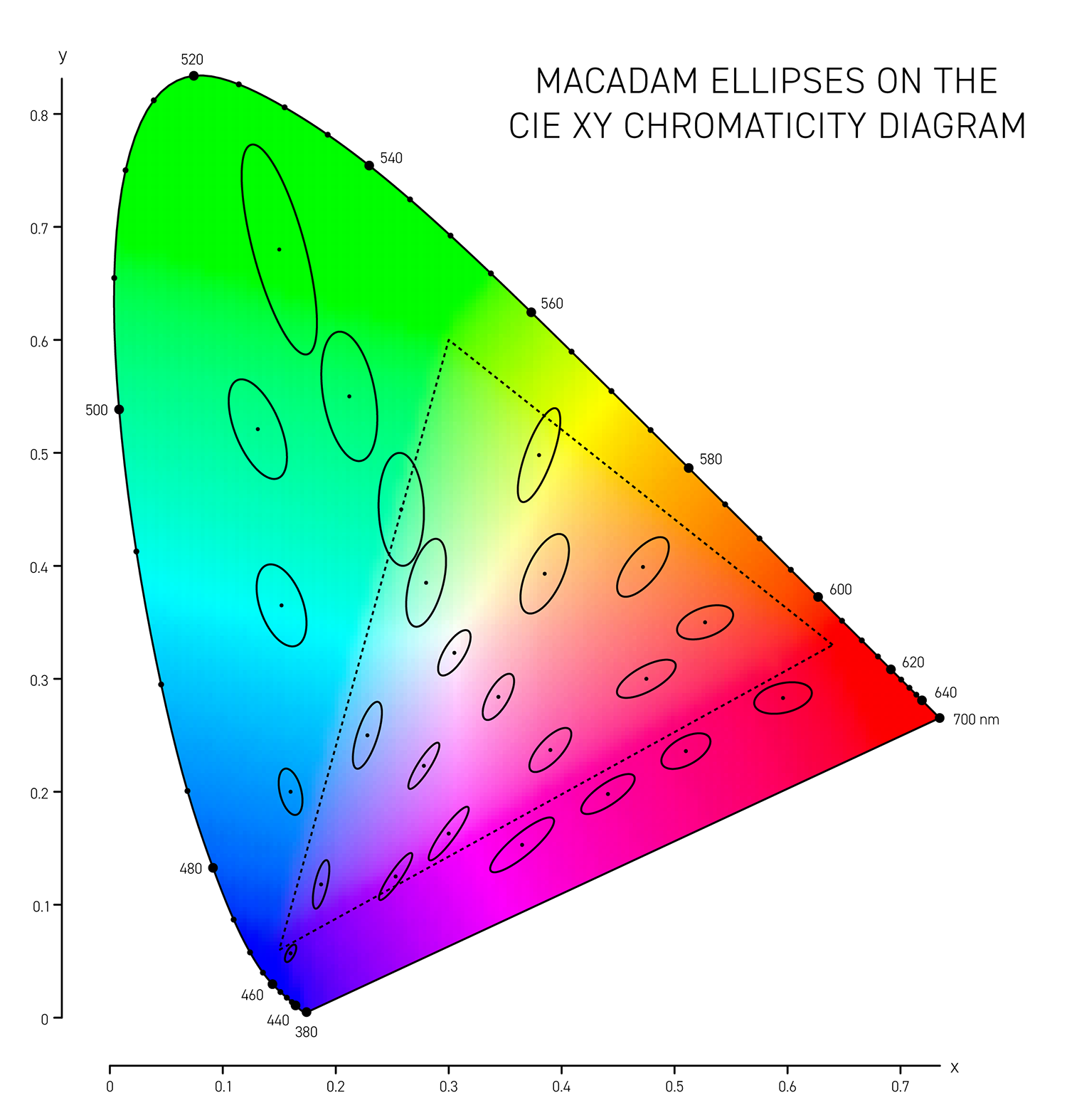
In 1942 D.L. MacAdam published Visual sensitivities to color differences in daylight in which he demarcated regions of indistinguishable colors in CIE `xy` chromaticity space at 25 locations — these form the MacAdam ellipses (download ellipse positions).
The difference between colors is called delta E (`\Delta E`) and is expressed by a number of different formulas — each slightly better at incorporating how we perceive color differences.
The simplest is the CIE76 `\Delta E` and this is the Euclidian distance between two colors in the CIE Lab color space. The Lab space is not perceptually uniform so this formula, while doing a reasonable job overall, doesn't distinguish between the extent to which we see differences in colors that are very saturated (saturation in Lab is called chroma `C = \sqrt{a^2+b^2}`). A difference of `\Delta E_{76} = 2.3` is called the JND (just noticeable difference) and is considered the limit of color discrimination (on average).
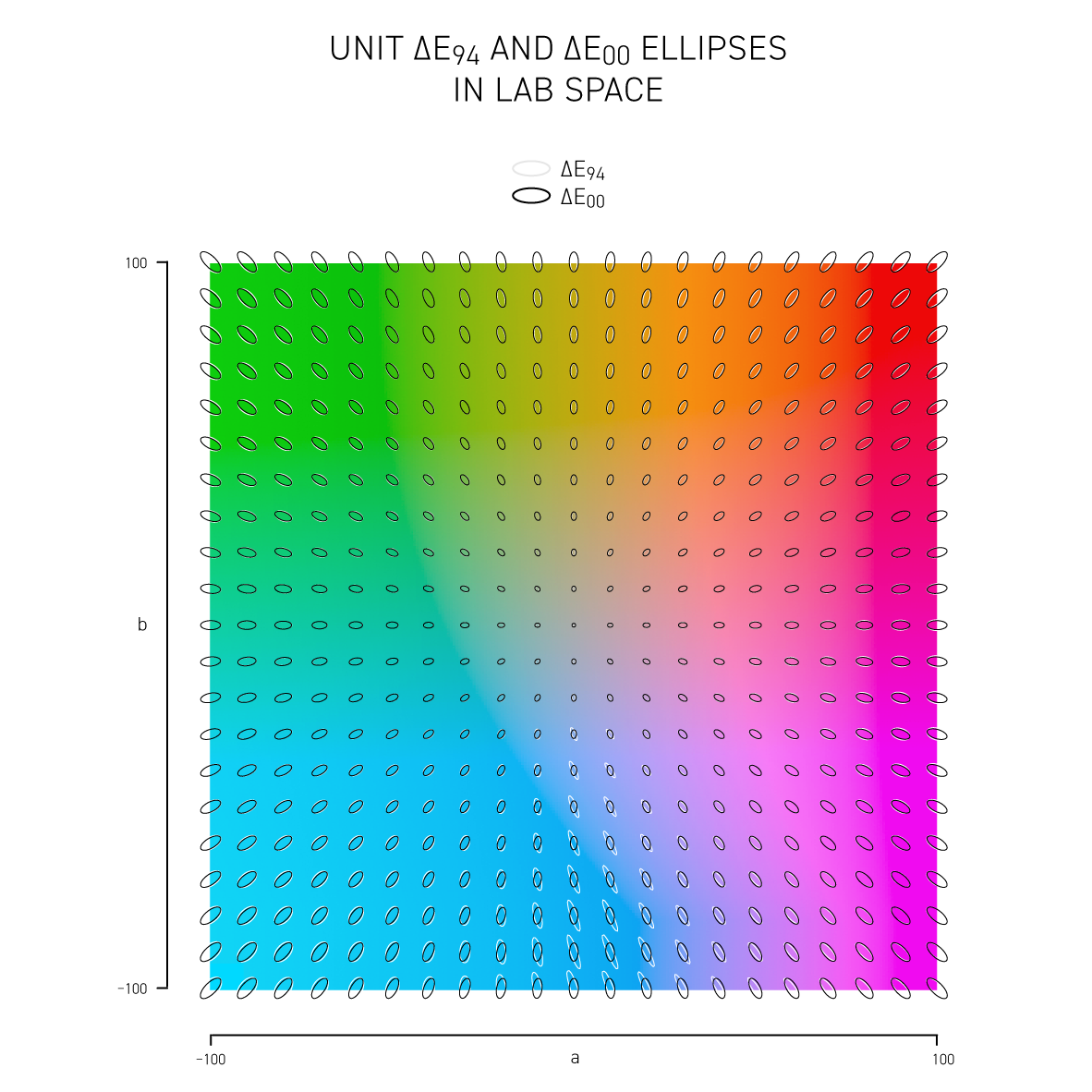
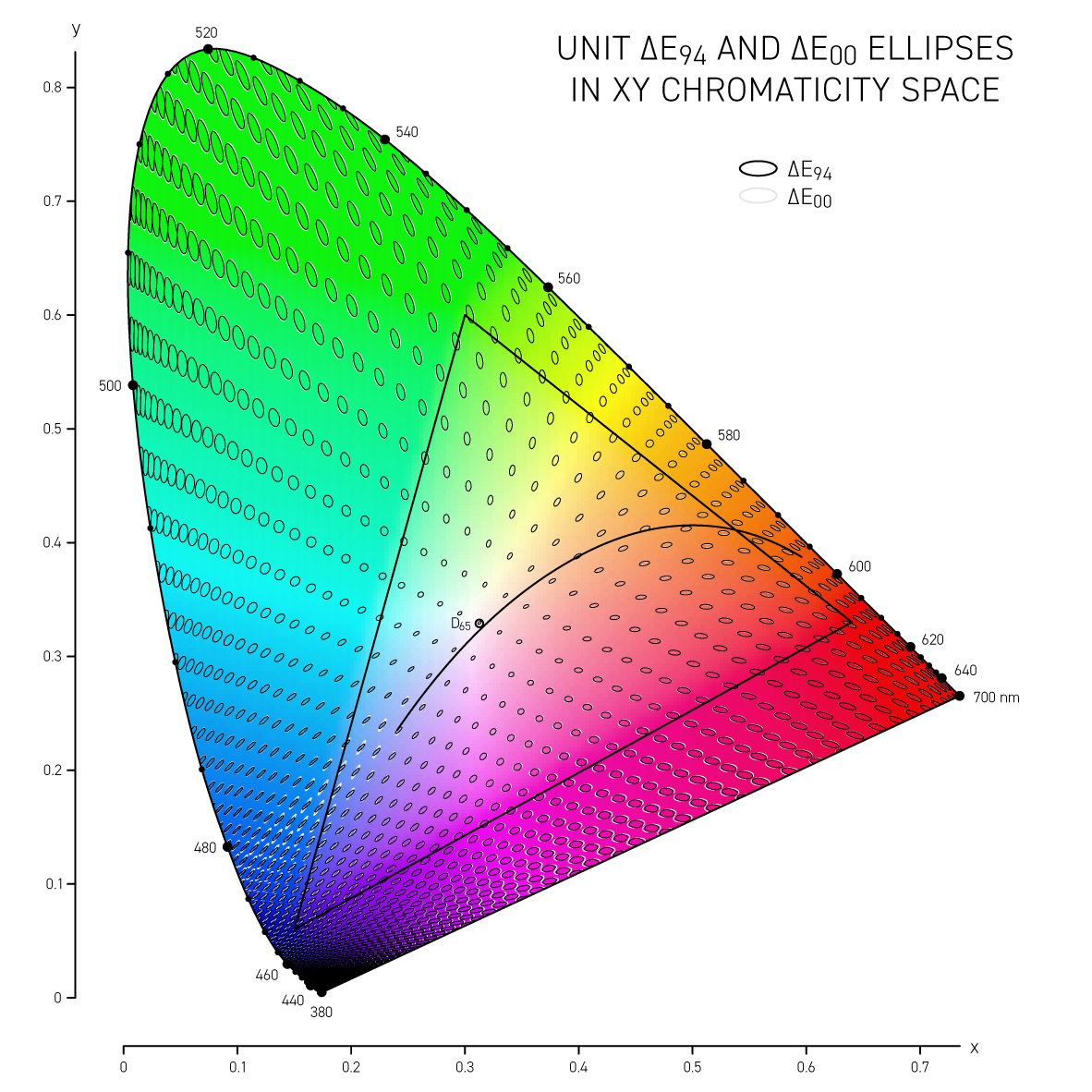
More sophisticated versions of `\Delta E` such as CIE94 and CIE00 attempt to address the non-uniformity of Lab space and with the aim to have a `\Delta E = 1` corresponds to a just noticeable difference (JND). Below, I show unit ellipses for CIE94 and CIE00 in Lab and `xy` chromaticity space — colors on the opposite side of an ellipse have a `\Delta E = 1`.
CIE94 and CIE00 are very similar to each other, except for blues and purples, where `\Delta E_{00}` ellipses are more eccentric and in the saturated greens where they are a little wider. In both cases the ellipses point in the direction of saturation — this corresponds to the fact that we discriminate hue better than saturation in Lab space. CIE00 is a more complicated calculation (and called by some an ugly calculation) and therefore slower — I'll guess that for most applications CIE94 is sufficient.
For more details about color differences see Colour difference `\Delta E` — A survey by W.S. Mokrzycki and M. Tatol.
Nasa to send our human genome discs to the Moon
We'd like to say a ‘cosmic hello’: mathematics, culture, palaeontology, art and science, and ... human genomes.



Comparing classifier performance with baselines
All animals are equal, but some animals are more equal than others. —George Orwell
This month, we will illustrate the importance of establishing a baseline performance level.
Baselines are typically generated independently for each dataset using very simple models. Their role is to set the minimum level of acceptable performance and help with comparing relative improvements in performance of other models.

Unfortunately, baselines are often overlooked and, in the presence of a class imbalance5, must be established with care.
Megahed, F.M, Chen, Y-J., Jones-Farmer, A., Rigdon, S.E., Krzywinski, M. & Altman, N. (2024) Points of significance: Comparing classifier performance with baselines. Nat. Methods 20.
Happy 2024 π Day—
sunflowers ho!
Celebrate π Day (March 14th) and dig into the digit garden. Let's grow something.

How Analyzing Cosmic Nothing Might Explain Everything
Huge empty areas of the universe called voids could help solve the greatest mysteries in the cosmos.
My graphic accompanying How Analyzing Cosmic Nothing Might Explain Everything in the January 2024 issue of Scientific American depicts the entire Universe in a two-page spread — full of nothing.

The graphic uses the latest data from SDSS 12 and is an update to my Superclusters and Voids poster.
Michael Lemonick (editor) explains on the graphic:
“Regions of relatively empty space called cosmic voids are everywhere in the universe, and scientists believe studying their size, shape and spread across the cosmos could help them understand dark matter, dark energy and other big mysteries.
To use voids in this way, astronomers must map these regions in detail—a project that is just beginning.
Shown here are voids discovered by the Sloan Digital Sky Survey (SDSS), along with a selection of 16 previously named voids. Scientists expect voids to be evenly distributed throughout space—the lack of voids in some regions on the globe simply reflects SDSS’s sky coverage.”
voids
Sofia Contarini, Alice Pisani, Nico Hamaus, Federico Marulli Lauro Moscardini & Marco Baldi (2023) Cosmological Constraints from the BOSS DR12 Void Size Function Astrophysical Journal 953:46.
Nico Hamaus, Alice Pisani, Jin-Ah Choi, Guilhem Lavaux, Benjamin D. Wandelt & Jochen Weller (2020) Journal of Cosmology and Astroparticle Physics 2020:023.
Sloan Digital Sky Survey Data Release 12
Alan MacRobert (Sky & Telescope), Paulina Rowicka/Martin Krzywinski (revisions & Microscopium)
Hoffleit & Warren Jr. (1991) The Bright Star Catalog, 5th Revised Edition (Preliminary Version).
H0 = 67.4 km/(Mpc·s), Ωm = 0.315, Ωv = 0.685. Planck collaboration Planck 2018 results. VI. Cosmological parameters (2018).
constellation figures
stars
cosmology
Error in predictor variables
It is the mark of an educated mind to rest satisfied with the degree of precision that the nature of the subject admits and not to seek exactness where only an approximation is possible. —Aristotle
In regression, the predictors are (typically) assumed to have known values that are measured without error.
Practically, however, predictors are often measured with error. This has a profound (but predictable) effect on the estimates of relationships among variables – the so-called “error in variables” problem.

Error in measuring the predictors is often ignored. In this column, we discuss when ignoring this error is harmless and when it can lead to large bias that can leads us to miss important effects.
Altman, N. & Krzywinski, M. (2024) Points of significance: Error in predictor variables. Nat. Methods 20.
Background reading
Altman, N. & Krzywinski, M. (2015) Points of significance: Simple linear regression. Nat. Methods 12:999–1000.
Lever, J., Krzywinski, M. & Altman, N. (2016) Points of significance: Logistic regression. Nat. Methods 13:541–542 (2016).
Das, K., Krzywinski, M. & Altman, N. (2019) Points of significance: Quantile regression. Nat. Methods 16:451–452.