It's Snowing in my CPU — a Snowflake catalogue
Now she was round and as pure as the morning light, crystal clear and like a tiny silver mirror she was able to catch and give back every colour in the world about her.
— Paul Gallico, Snowflake
Go ahead, meet some snowflakes.








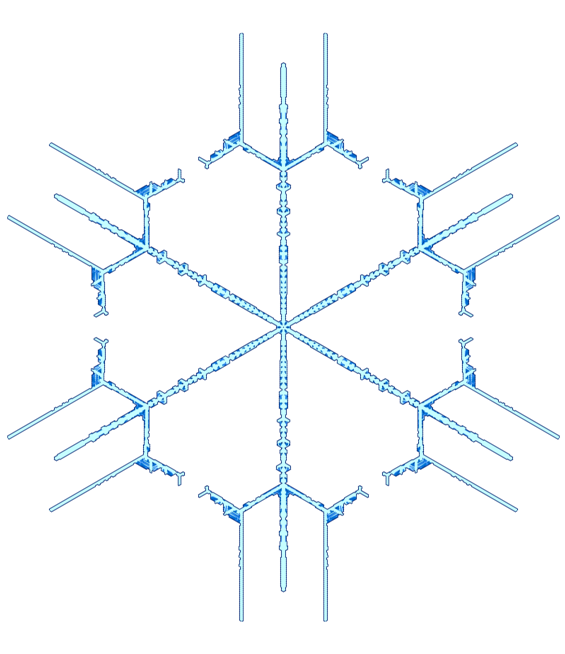
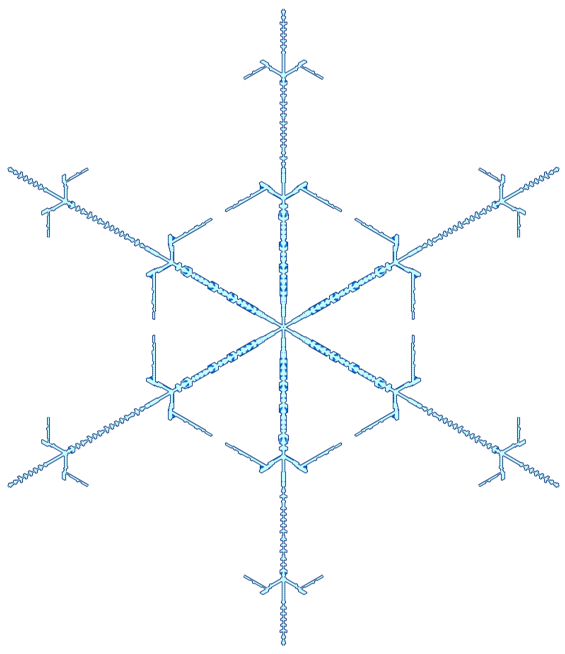
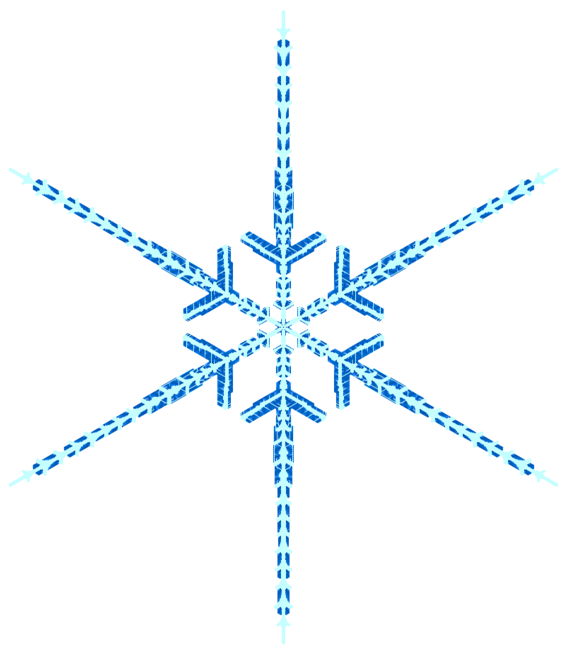
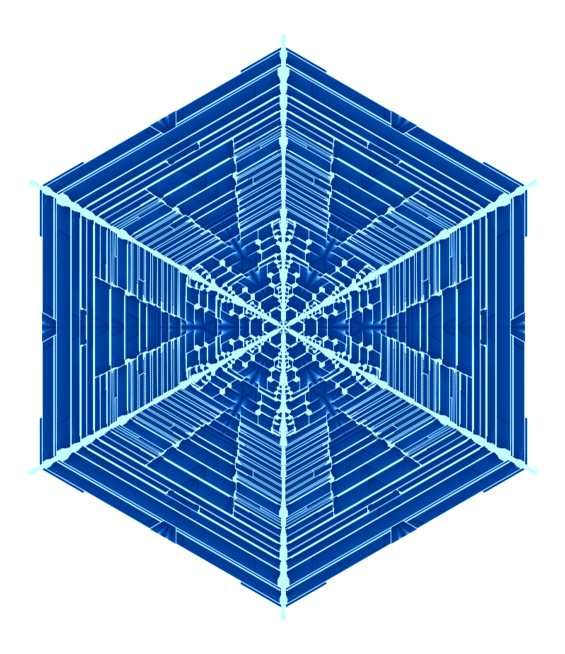
Somewhere in the world, it's snowing. But you don't need to go far—it's always snowing on this page. Explore random flurries, snowflake families and individual flakes. There are many unusual snowflakes and snowflake family 12 and family 46 are very interesting.
But don't settle for only pixel snowflakes—make an STL file and 3D print your own flakes!
Ad blockers may interfere with some flake images—the names of flakes can trigger ad filters.
And if after reading about my flakes you want more, get your frozen fix with Kenneth Libbrecht's excellent work and Paul Gallico's Snowflake.
All flakes are unique but some are more unique than others. Here are some of them—hand-picked—grouped by gender and arranged alphabetically by their name.
the odd girl snowflakes

























































the odd boy snowflakes