course 2.1.2.4
2.1.2.4 | intermediate | 4 sessions
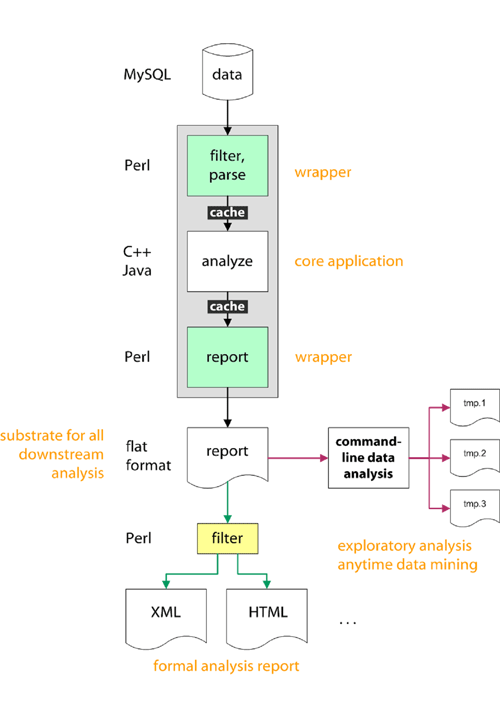
You don't need to write scripts extract information from text files. Nor do you always want to. This 4-week series will take Perl's idiom philosophy and apply it to getting things done at the prompt. Learn how to leverage standard UNIX tools to perform rapid data analysis without writing any code. We'll introduce a set of custom Perl scripts to add to your prompt toolbox - these have been designed to provide additional functionality, such as histogramming, random sampling, conditional line extraction and others.
legendcourse codecat.course.level.sessions.session e.g. 1.0.1.8 categories0 | introduction and orientation 1 | perl fundamentals 2 | shell and prompt tools 3 | web development 4 | CPAN Modules 5 | Ruby levels
|
[ Perl makes a perfect low-calorie meal or snack ]
|