





visualization + design
Getting into Visualization of Large Biological Data Sets
The 20 imperatives of information design
Martin Krzywinski, Inanc Birol, Steven Jones, Marco Marra
Presented at Biovis 2012 (Visweek 2012). Content is drawn from my book chapter Visualization Principles for Scientific Communication (Martin Krzywinski & Jonathan Corum) in the upcoming open access Cambridge Press book Visualizing biological data - a practical guide (Seán I. O'Donoghue, James B. Procter, Kate Patterson, eds.), a survey of best practices and unsolved problems in biological visualization. This book project was conceptualized and initiated at the Vizbi 2011 conference.
If you are interested in guidelines for data encoding and visualization in biology, see our Visualization Principles Vizbi 2012 Tutorial and Nature Methods Points of View column by Bang Wong.
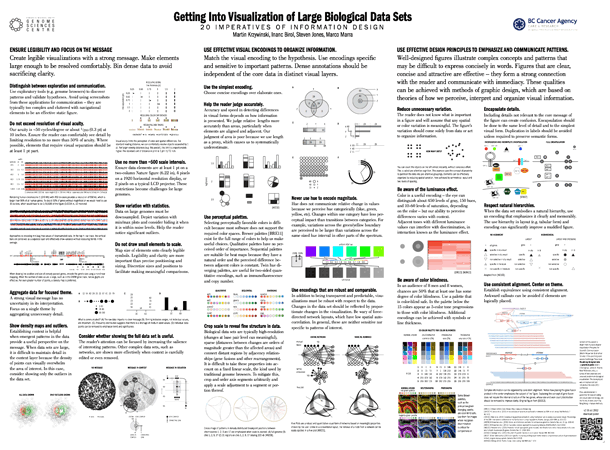
ENSURE LEGIBILITY AND FOCUS ON THE MESSAGE
Create legible visualizations with a strong message. Make elements large enough to be resolved comfortably. Bin dense data to avoid sacrificing clarity.
Distinguish between exploration and communication.
Use exploratory tools (e.g. genome browsers) to discover patterns and validate hypotheses. Avoid using screenshots from these applications for communication – they are typically too complex and cluttered with navigational elements to be an effective static figure.
Do not exceed resolution of visual acuity.
Our acuity is ~50 cycles/degree or about 1/200 (0.3 pt) at 10 inches. Ensure the reader can comfortably see detail by limiting resolution to no more than 50% of acuity. Where possible, elements that require visual separation should be at least 1 pt part.
Use no more than ~500 scale intervals.
Ensure data elements are at least 1 pt on a two-column Nature figure (6.22 in), 4 pixels on a 1920 horizontal resolution display, or 2 pixels on a typical LCD projector. These restrictions become challenges for large genomes.
Show variation with statistics.
Data on large genomes must be downsampled. Depict variation with min/max plots and consider hiding it when it is within noise levels. Help the reader notice significant outliers.
Do not draw small elements to scale.
Map size of elements onto clearly legible symbols. Legibility and clarity are more important than precise positioning and sizing. Discretize sizes and positions to facilitate making meaningful comparisons.
Aggregate data for focused theme.
A strong visual message has no uncertainty in its interpretation. Focus on a single theme by aggregating unnecessary detail.
Show density maps and outliers.
Establishing context is helpful when emergent patterns in the data provide a useful perspective on the message. When data sets are large, it is difficult to maintain detail in the context layer because the density of points can visually overwhelm the area of interest. In this case, consider showing only the outliers in the data set.
Consider whether showing the full data set is useful.
The reader’s attention can be focused by increasing the salience of interesting patterns. Other complex data sets, such as networks, are shown more effectively when context is carefully edited or even removed.
USE EFFECTIVE VISUAL ENCODINGS TO ORGANIZE INFORMATION.
Match the visual encoding to the hypothesis. Use encodings specific and sensitive to important patterns. Dense annotations should be independent of the core data in distinct visual layers.
Use the simplest encoding.
Choose concise encodings over elaborate ones.
Help the reader judge accurately.
Accuracy and speed in detecting differences in visual forms depends on how information is presented. We judge relative lengths more accurately than areas, particularly when elements are aligned and adjacent. Our judgment of area is poor because we use length as a proxy, which causes us to systematically underestimate.
Use encodings that are robust and comparable.
In addition to being transparent and predictable, visualizations must be robust with respect to the data. Changes in the data set should be reflected by proportionate changes in the visualization. Be wary of force-directed network layouts, which have low spatial autocorrelation. In general, these are neither sensitive nor specific to patterns of interest.
Crop scale to reveal fine structure in data.
Biological data sets are typically high-resolution (changes at base pair level can meaningful), sparse (distances between changes are orders of magnitude greater than the affected areas) and connect distant regions by adjacency relationships (gene fusions and other rearrangements). It is difficult to take these properties into account on a fixed linear scale, the kind used by traditional genome browsers. To mitigate this, crop and order axis segments arbitrarily and apply a scale adjustment to a segment or portion thereof.Use perceptual palettes.
Selecting perceptually favorable colors is difficult because most software does not support the required color spaces. Brewer palettes exist for the full range of colors to help us make useful choices. Qualitative palettes have no perceived order of importance. Sequential palettes are suitable for heat maps because they have a natural order and the perceived difference between adjacent colors is constant. Twin hue diverging palettes, are useful for two-sided quantitative encodings, such as immunofluorescence and copy number.Never use hue to encode magnitude.
Hue does not communicate relative change in values because we perceive hue categorically (blue, green, yellow, etc). Changes within one category have less perceptual impact than transitions between categories. For example, variations across the green/yellow boundary are perceived to be larger than variations across the same sized hue interval in other parts of the spectrum.USE EFFECTIVE DESIGN PRINCIPLES TO EMPHASIZE AND COMMUNICATE PATTERNS.
Well-designed figures illustrate complex concepts and patterns that may be difficult to express concisely in words. Figures that are clear, concise and attractive are effective – they form a strong connection with the reader and communicate with immediacy. These qualities can be achieved with methods of graphic design, which are based on theories of how we perceive, interpret and organize visual information.
Reduce unnecessary variation.
The reader does not know what is important in a figure and will assume that any spatial or color variation is meaningful. The figure’s variation should come solely from data or act to organize information.
Encapsulate details.
Including details not relevant to the core message of the figure can create confusion. Encapsulation should be done to the same level of detail and to the simplest visual form. Duplication in labels should be avoided.
Use consistent alignment. Center on theme.
Establish equivalence using consistent alignment. Awkward callouts can be avoided if elements are logically placed.Respect natural hierarchies.
When the data set embodies a natural hierarchy, use an encoding that emphasizes it clearly and memorably. The use hierarchy in layout (e.g. tabular form) and encoding can significantly improve a muddled figure.
Be aware of the luminance effect.
Color is a useful encoding – the eye can distinguish about 450 levels of gray, 150 hues, and 10-60 levels of saturation, depending on the color – but our ability to perceive differences varies with context. Adjacent tones with different luminance values can interfere with discrimination, in interaction known as the luminance effect.
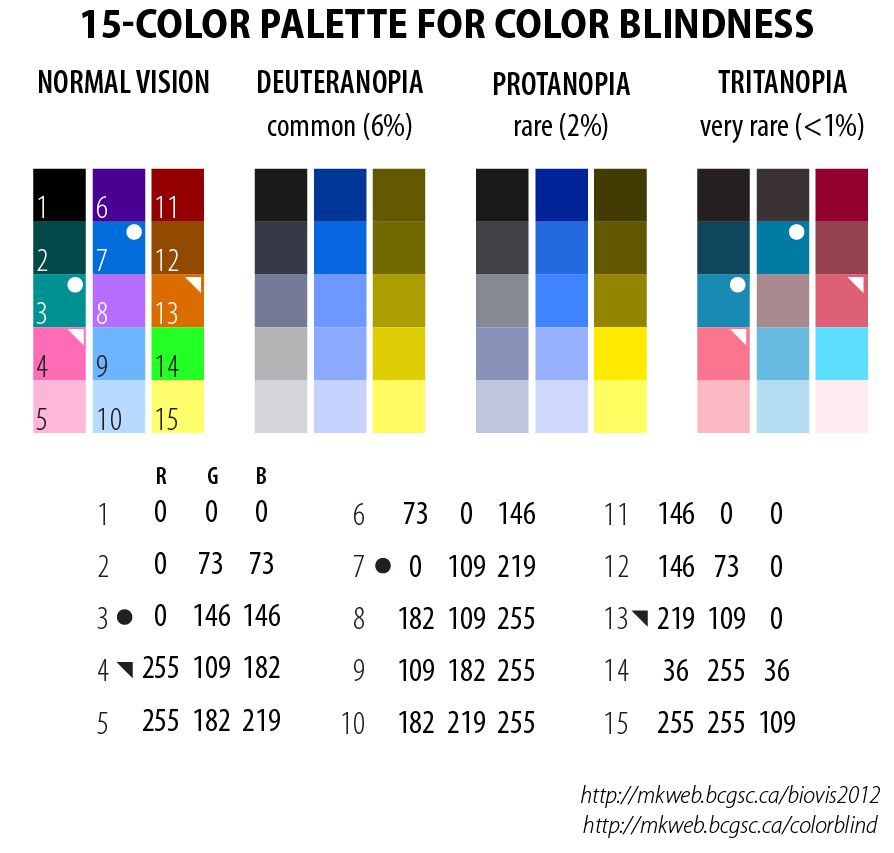
Be aware of color blindness.
In an audience of 8 men and 8 women, chances are 50% that at least one has some degree of color blindness. Use a palette that is color-blind safe. In the palette below the 15 colors appear as 5-color tone progressions to those with color blindness. Additional encodings can be achieved with symbols or line thickness.
I have designed 15-color palettes for color blindess for each of the three common types of color blindness.
Nasa to send our human genome discs to the Moon
We'd like to say a ‘cosmic hello’: mathematics, culture, palaeontology, art and science, and ... human genomes.



Comparing classifier performance with baselines
All animals are equal, but some animals are more equal than others. —George Orwell
This month, we will illustrate the importance of establishing a baseline performance level.
Baselines are typically generated independently for each dataset using very simple models. Their role is to set the minimum level of acceptable performance and help with comparing relative improvements in performance of other models.

Unfortunately, baselines are often overlooked and, in the presence of a class imbalance5, must be established with care.
Megahed, F.M, Chen, Y-J., Jones-Farmer, A., Rigdon, S.E., Krzywinski, M. & Altman, N. (2024) Points of significance: Comparing classifier performance with baselines. Nat. Methods 20.
Happy 2024 π Day—
sunflowers ho!
Celebrate π Day (March 14th) and dig into the digit garden. Let's grow something.

How Analyzing Cosmic Nothing Might Explain Everything
Huge empty areas of the universe called voids could help solve the greatest mysteries in the cosmos.
My graphic accompanying How Analyzing Cosmic Nothing Might Explain Everything in the January 2024 issue of Scientific American depicts the entire Universe in a two-page spread — full of nothing.

The graphic uses the latest data from SDSS 12 and is an update to my Superclusters and Voids poster.
Michael Lemonick (editor) explains on the graphic:
“Regions of relatively empty space called cosmic voids are everywhere in the universe, and scientists believe studying their size, shape and spread across the cosmos could help them understand dark matter, dark energy and other big mysteries.
To use voids in this way, astronomers must map these regions in detail—a project that is just beginning.
Shown here are voids discovered by the Sloan Digital Sky Survey (SDSS), along with a selection of 16 previously named voids. Scientists expect voids to be evenly distributed throughout space—the lack of voids in some regions on the globe simply reflects SDSS’s sky coverage.”
voids
Sofia Contarini, Alice Pisani, Nico Hamaus, Federico Marulli Lauro Moscardini & Marco Baldi (2023) Cosmological Constraints from the BOSS DR12 Void Size Function Astrophysical Journal 953:46.
Nico Hamaus, Alice Pisani, Jin-Ah Choi, Guilhem Lavaux, Benjamin D. Wandelt & Jochen Weller (2020) Journal of Cosmology and Astroparticle Physics 2020:023.
Sloan Digital Sky Survey Data Release 12
Alan MacRobert (Sky & Telescope), Paulina Rowicka/Martin Krzywinski (revisions & Microscopium)
Hoffleit & Warren Jr. (1991) The Bright Star Catalog, 5th Revised Edition (Preliminary Version).
H0 = 67.4 km/(Mpc·s), Ωm = 0.315, Ωv = 0.685. Planck collaboration Planck 2018 results. VI. Cosmological parameters (2018).
constellation figures
stars
cosmology
Error in predictor variables
It is the mark of an educated mind to rest satisfied with the degree of precision that the nature of the subject admits and not to seek exactness where only an approximation is possible. —Aristotle
In regression, the predictors are (typically) assumed to have known values that are measured without error.
Practically, however, predictors are often measured with error. This has a profound (but predictable) effect on the estimates of relationships among variables – the so-called “error in variables” problem.

Error in measuring the predictors is often ignored. In this column, we discuss when ignoring this error is harmless and when it can lead to large bias that can leads us to miss important effects.
Altman, N. & Krzywinski, M. (2024) Points of significance: Error in predictor variables. Nat. Methods 20.
Background reading
Altman, N. & Krzywinski, M. (2015) Points of significance: Simple linear regression. Nat. Methods 12:999–1000.
Lever, J., Krzywinski, M. & Altman, N. (2016) Points of significance: Logistic regression. Nat. Methods 13:541–542 (2016).
Das, K., Krzywinski, M. & Altman, N. (2019) Points of significance: Quantile regression. Nat. Methods 16:451–452.