
`\pi` Day 2016 Art Posters









On March 14th celebrate `\pi` Day. Hug `\pi`—find a way to do it.
For those who favour `\tau=2\pi` will have to postpone celebrations until July 26th. That's what you get for thinking that `\pi` is wrong. I sympathize with this position and have `\tau` day art too!
If you're not into details, you may opt to party on July 22nd, which is `\pi` approximation day (`\pi` ≈ 22/7). It's 20% more accurate that the official `\pi` day!
Finally, if you believe that `\pi = 3`, you should read why `\pi` is not equal to 3.

This year's `\pi` day art collection celebrates not only the digit but also one of the fundamental forces in nature: gravity.
In February of 2016, for the first time, gravitational waves were detected at the Laser Interferometer Gravitational-Wave Observatory (LIGO).
The signal in the detector was sonified—a process by which any data can be encoded into sound to provide hints at patterns and structure that we might otherwise miss—and we finally heard what two black holes sound like. A buzz and chirp.
The art is featured in the Gravity of Pi article on the Scientific American SA Visual blog.
this year's theme music
All the art was processed while listening to Roses by Coeur de Pirate, a brilliant female French-Canadian songwriter, who sounds like a mix of Patricia Kaas and Lhasa. The lyrics Oublie-moi (Forget me) are fitting with this year's theme of gravity.
Mais laisse-moi tomber, laisse-nous tomber
Laisse la nuit trembler en moi
Laisse-moi tomber, laisse nous tomber
Cette fois
But let me fall, let us fall
Let the night tremble in me
Let me fall, let us fall
This time
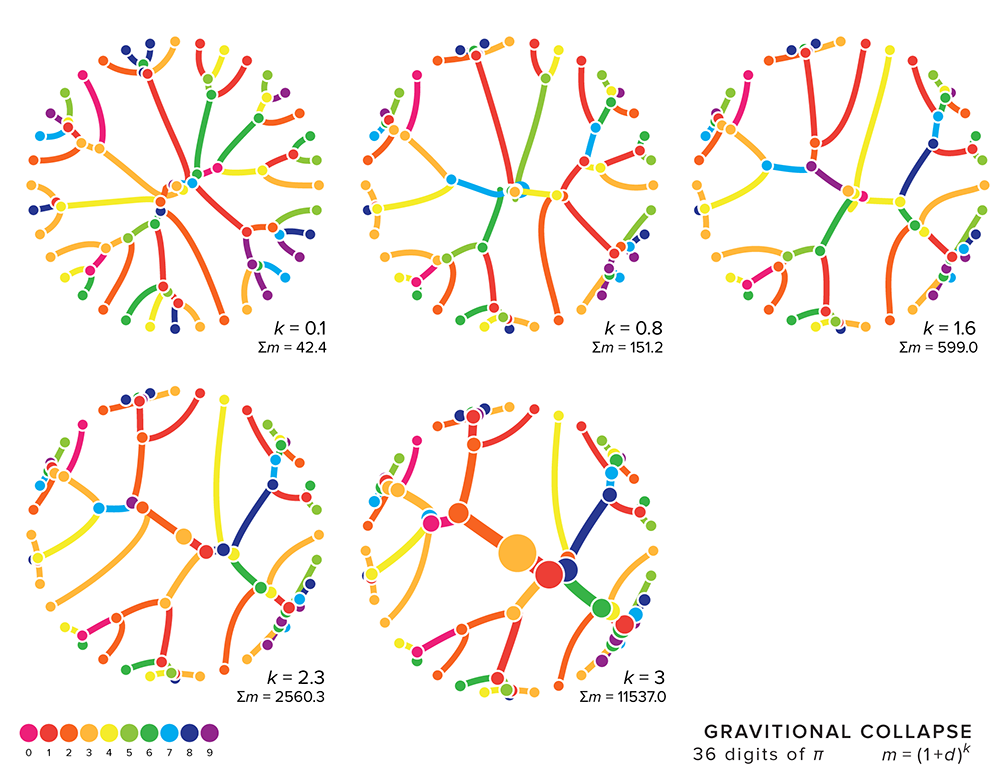
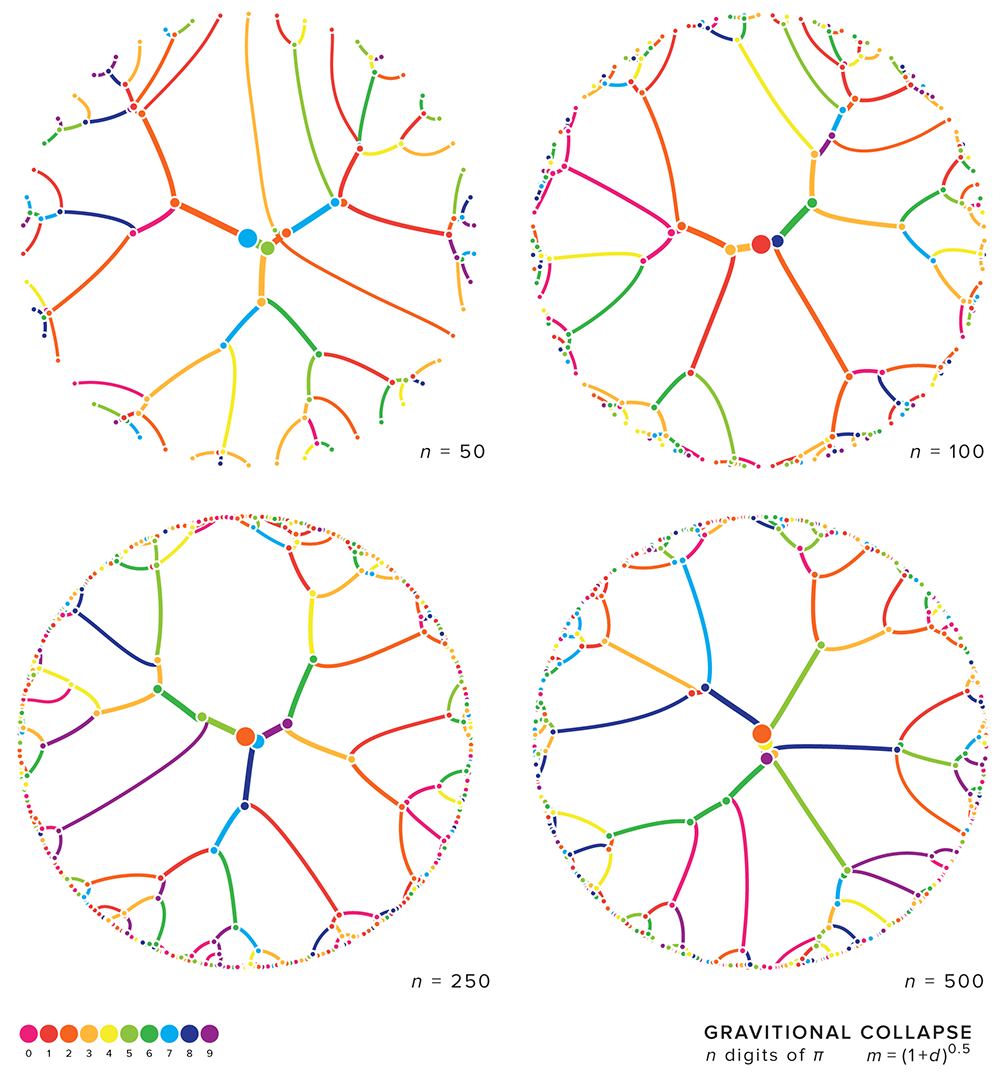
The art is generated by running a simulation of gravity in which digits of `\pi` are each assigned a mass and allowed to collide eand orbit each other.
The mathematical details of the simulation can be found in the code section.
exploring force of gravity in `\pi`
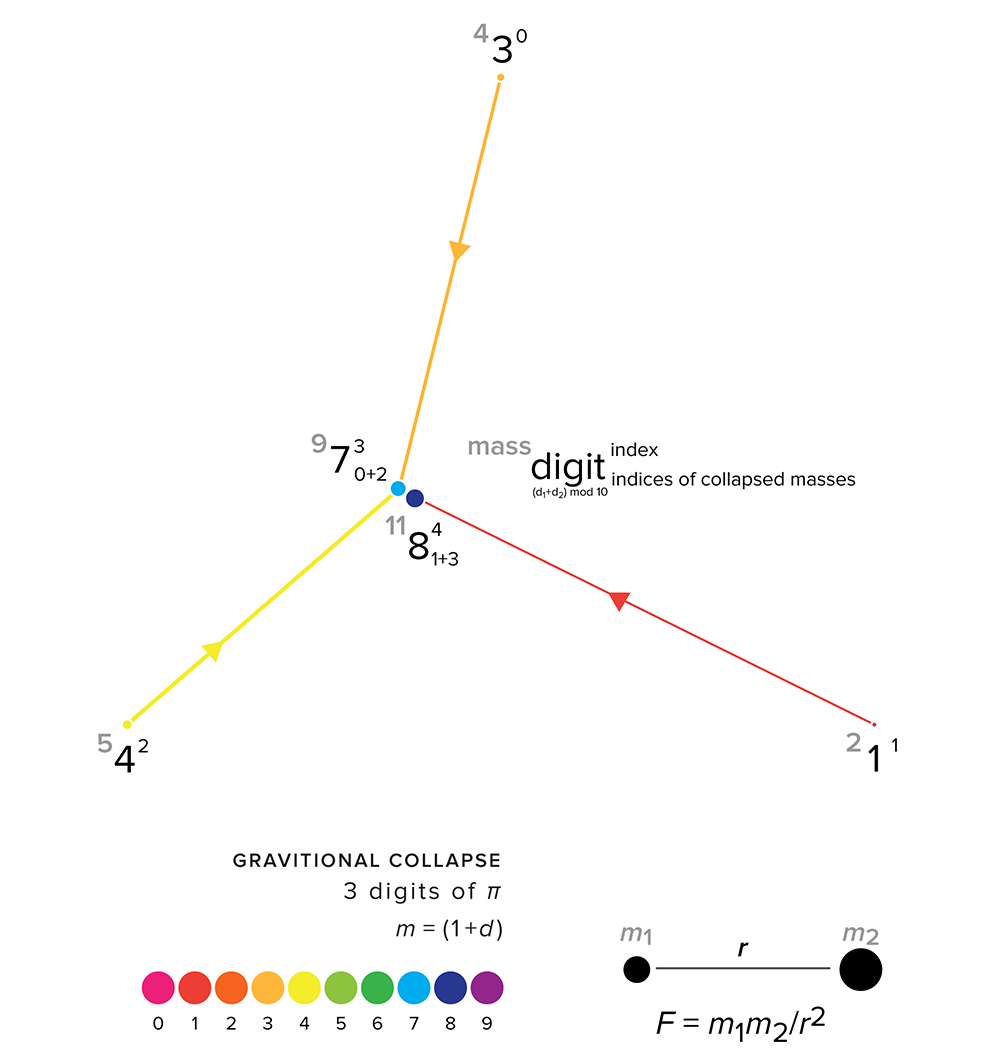
A simulation starts with taking `n` digits of `\pi` and arranging them uniformly around a circle. The mass of each digit, `d_i` (e.g. 3), is given by `(1+d)^k` where `k` is a mass power parameter between 0.01 and 1. For example, if `k=0.42` then the mass of 3 is `(1+3)^{0.42} = 1.79`.
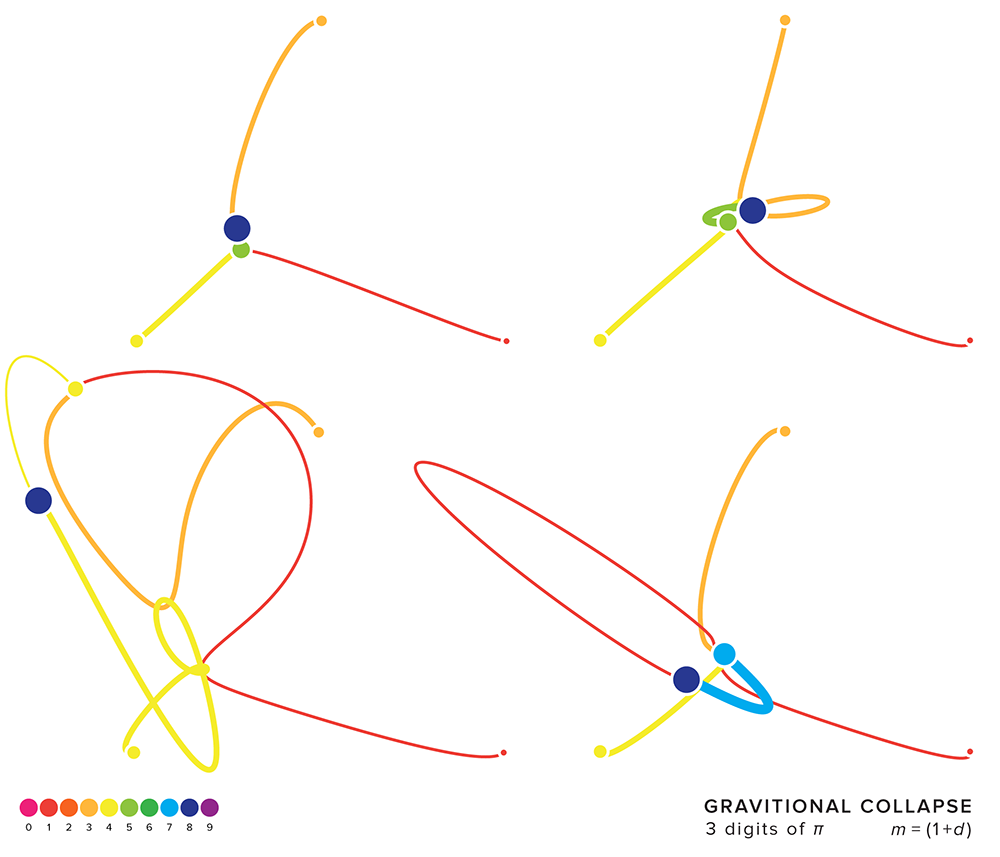
collapsing three digits—3.14 collide
The figure below shows the evolution of a simulation with `n=3` digits and `k=1`. The digits 3 and 4 collide to form the digit `3+4 = 7` and immediately collides with 1 to form `7+1=8`. With only one mass left in the system, the simulation stops.
adding initial velocity to each mass
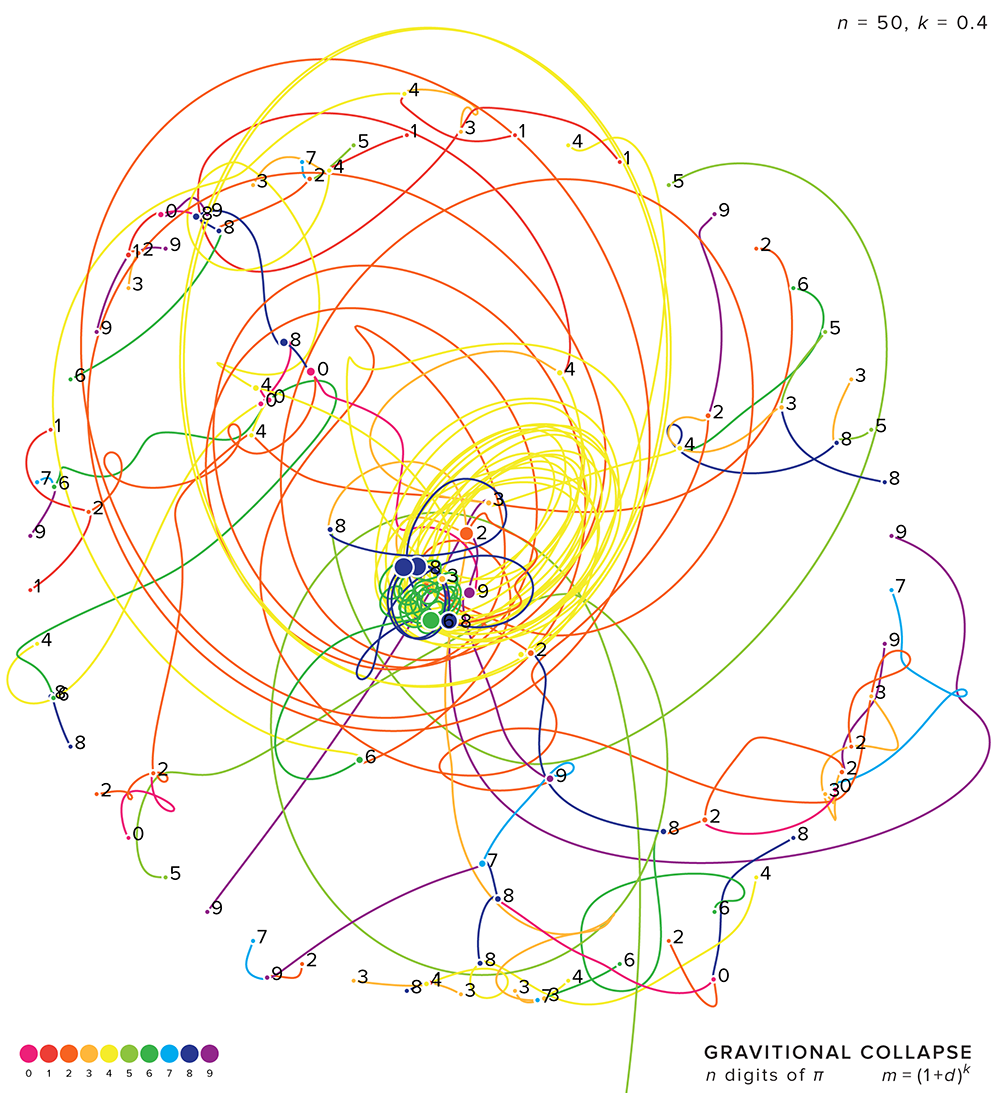
When masses have initial velocities, the patterns quickly start to get interesting. In the figure above, the masses are initalized with zero velocity. As soon as the simulation, each mass immediately starts to move directly towards the center of mass of the other two masses.
When the initial velocity is non-zero, such as in the figure below, the masses don't immediately collapse towards one another. The masses first travel with their initial velocity but immediately the gravitational force imparts acceleration that alters this velocity. In the examples below, only those simulations in which the masses collapsed within a time cutoff are shown.
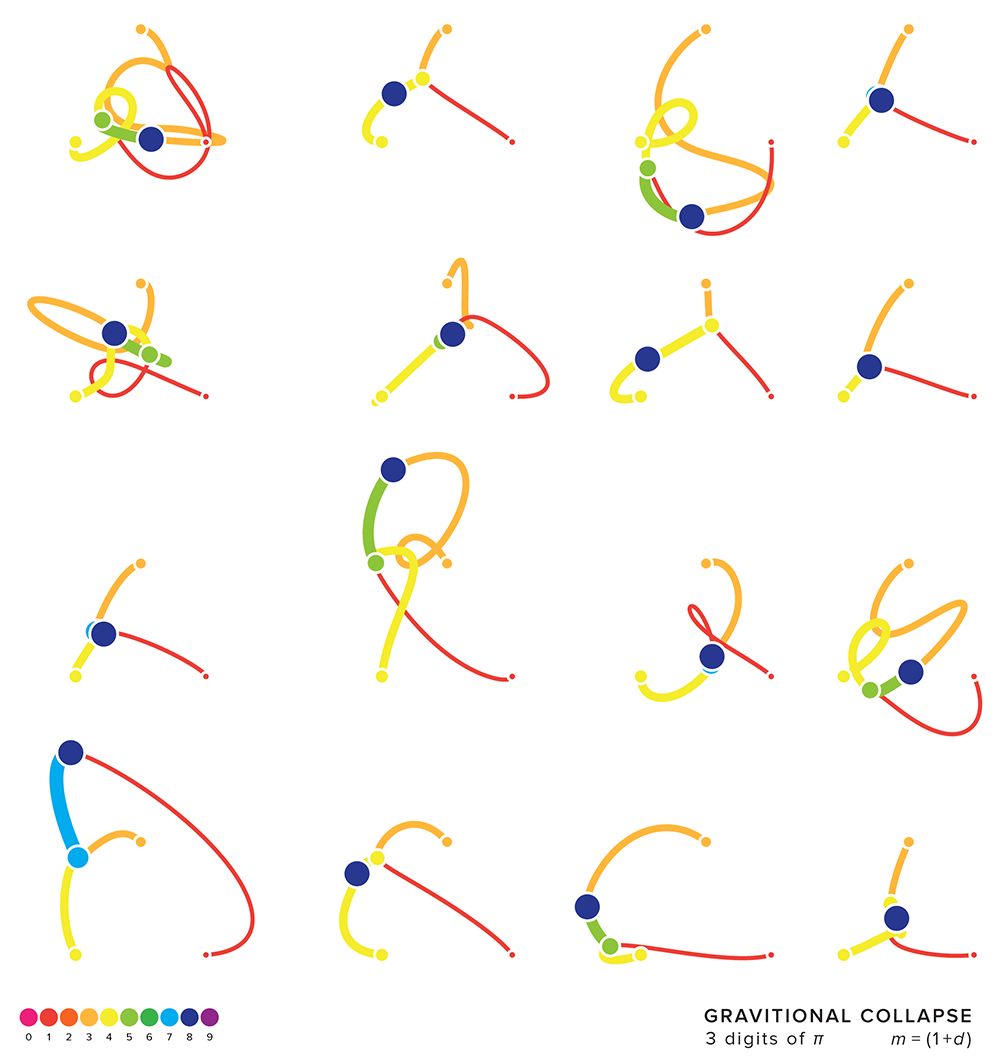
allowing the simulation to evolve
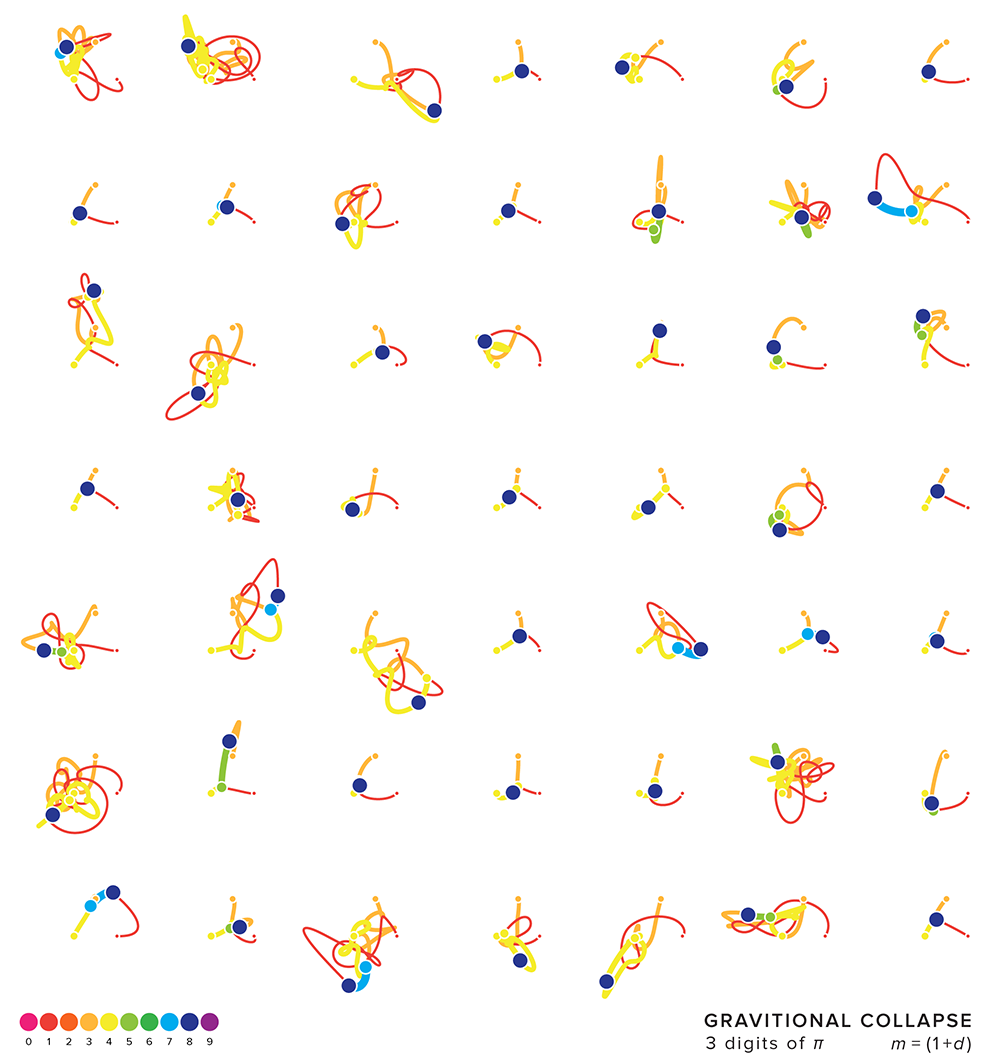
Depending on the initial velocities, some systems collapse very quickly, which doesn't make for interesting patterns.
For example, the simulations above evolved over 100,000 steps and in some cases the masses collapsed within 10,000 steps. In the figure below, I require that the system evolves for at least 15,000 steps before collapsing. Lovely doddles, don't you think?

exploring ensembles
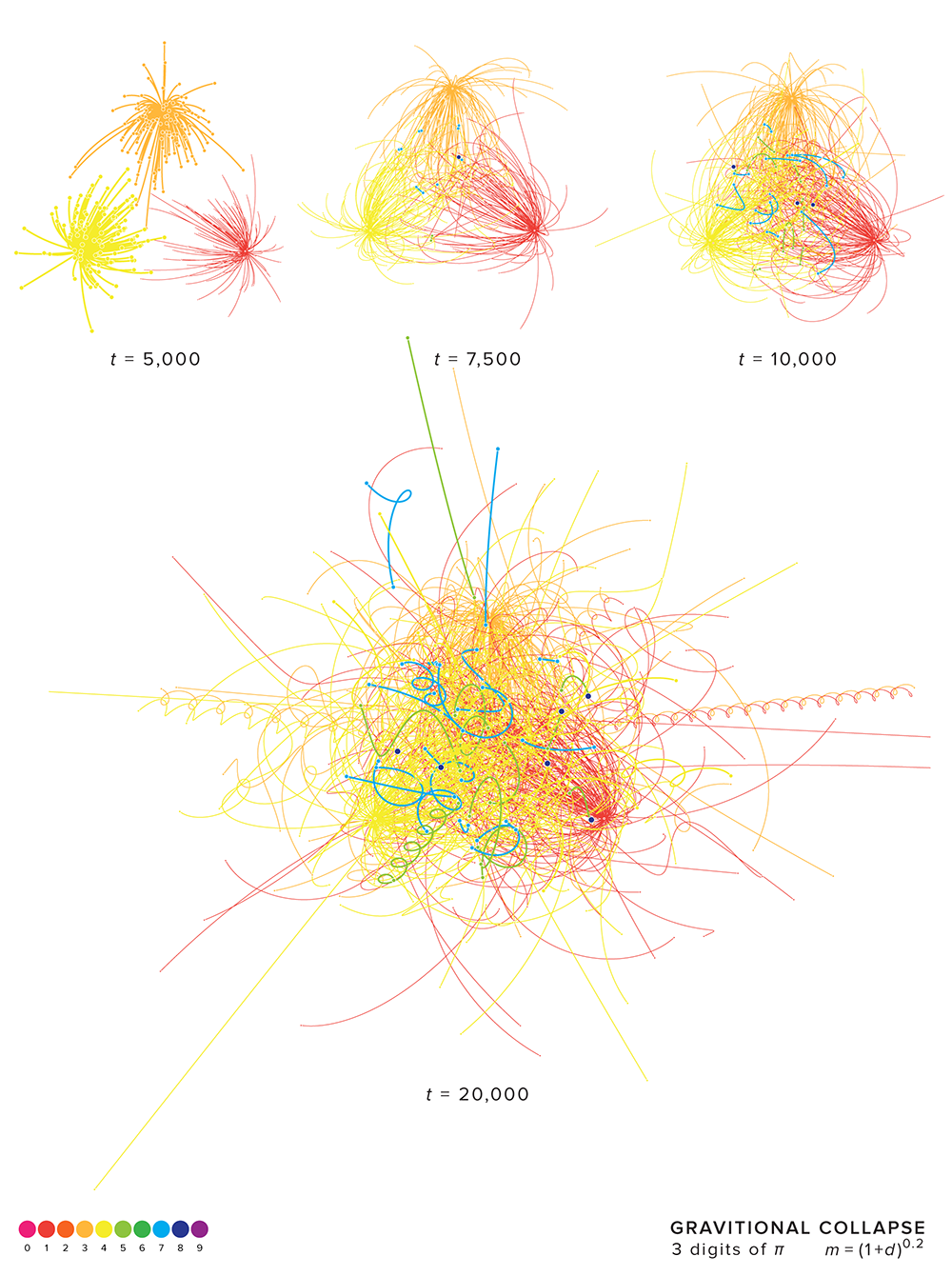
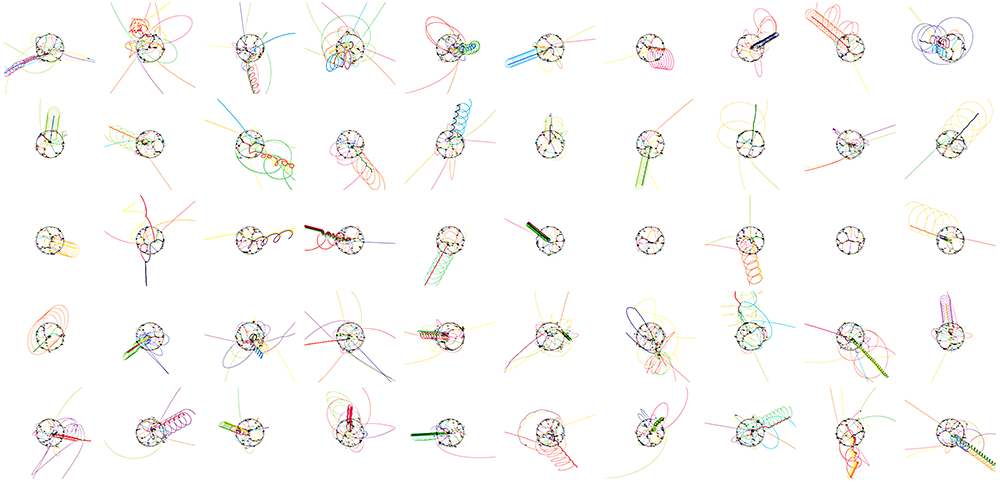
When a simulation is repeated with different initial conditions, the set of outcomes is called an ensemble.
Below, I repeat the simulation 100 times with `n=3` and `k=0.2`, each time with slightly different initial velocity. The velocities have their `x`- and `y`-components normally distributed with zero mean and a fixed variance. Each of the four ensembles has its simulations evolve over progressively more time steps: 5,000, 7,500, 10,000, and 20,000.
You can see that with 5,000 steps the masses don't yet have a chance to collide. After 7,500, there have been collisions in a small number of systems. The blue mass corresponds to the 3 colliding with 4 and the green mass to 1 colliding with 4. After 10,000, even more collisions are seen and in 3 cases we see total collapse (all three digits collided). After 20,000,
varying masses
The value of `k` greatly impacts the outcome of the simulation. When `k` is very small, all the digits have essentially the same mass. For example, when `k=0.01` the 0 has a mass of 1 and 9 has a mass of 1.02.
When `k` is large, the difference in masses is much greater. For example, for `k=2` the lightest mass is `(1+0)^2=1` and the heaviest `(1+9)^2=10`. Because the acceleration of a mass is proportional to the mass that is attracting it, in a pair of masses the light mass will accelerate faster.
increasing number of masses
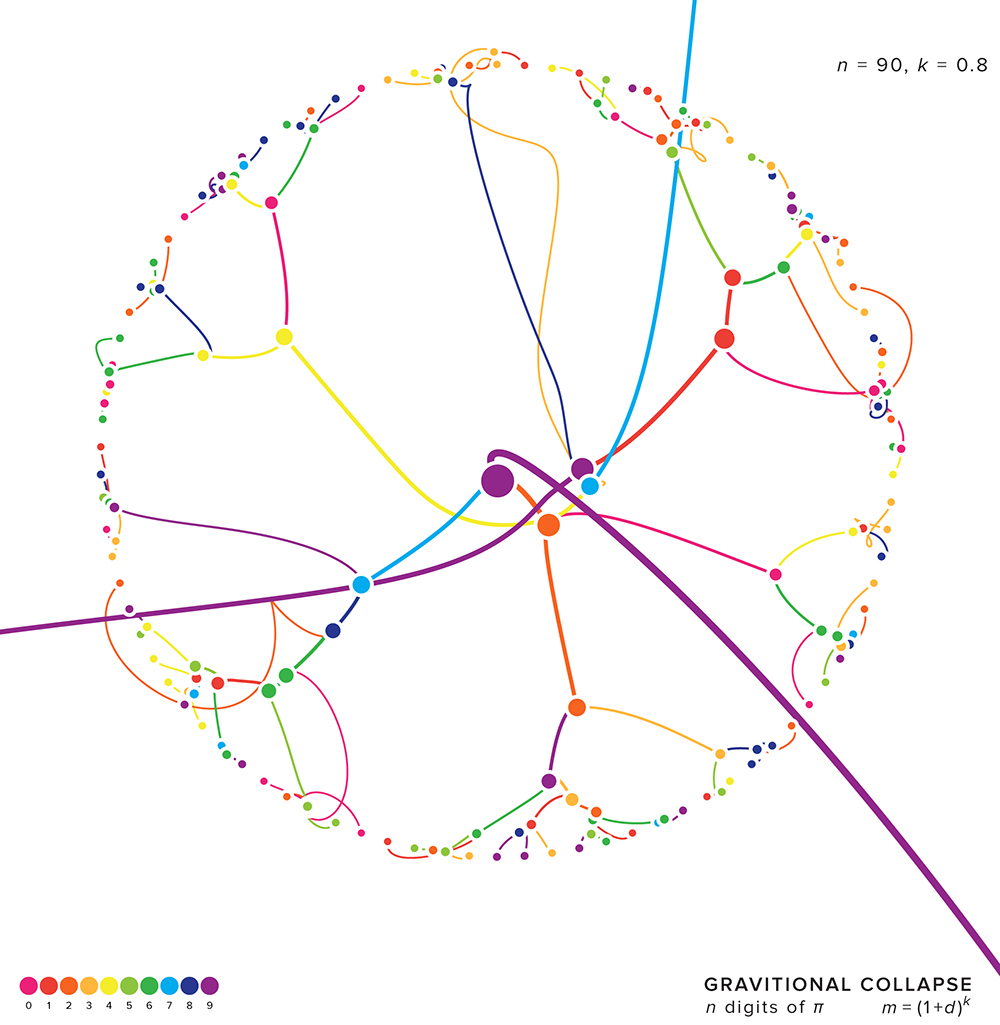
As the number of digits is increased, the pattern of collapse doesn't qualitatively change.
gravity makes beautiful doodles
I ran a large number of simulations. For various values of `n` and `k`, I repeated the simulation several times to sample different intial velocities.
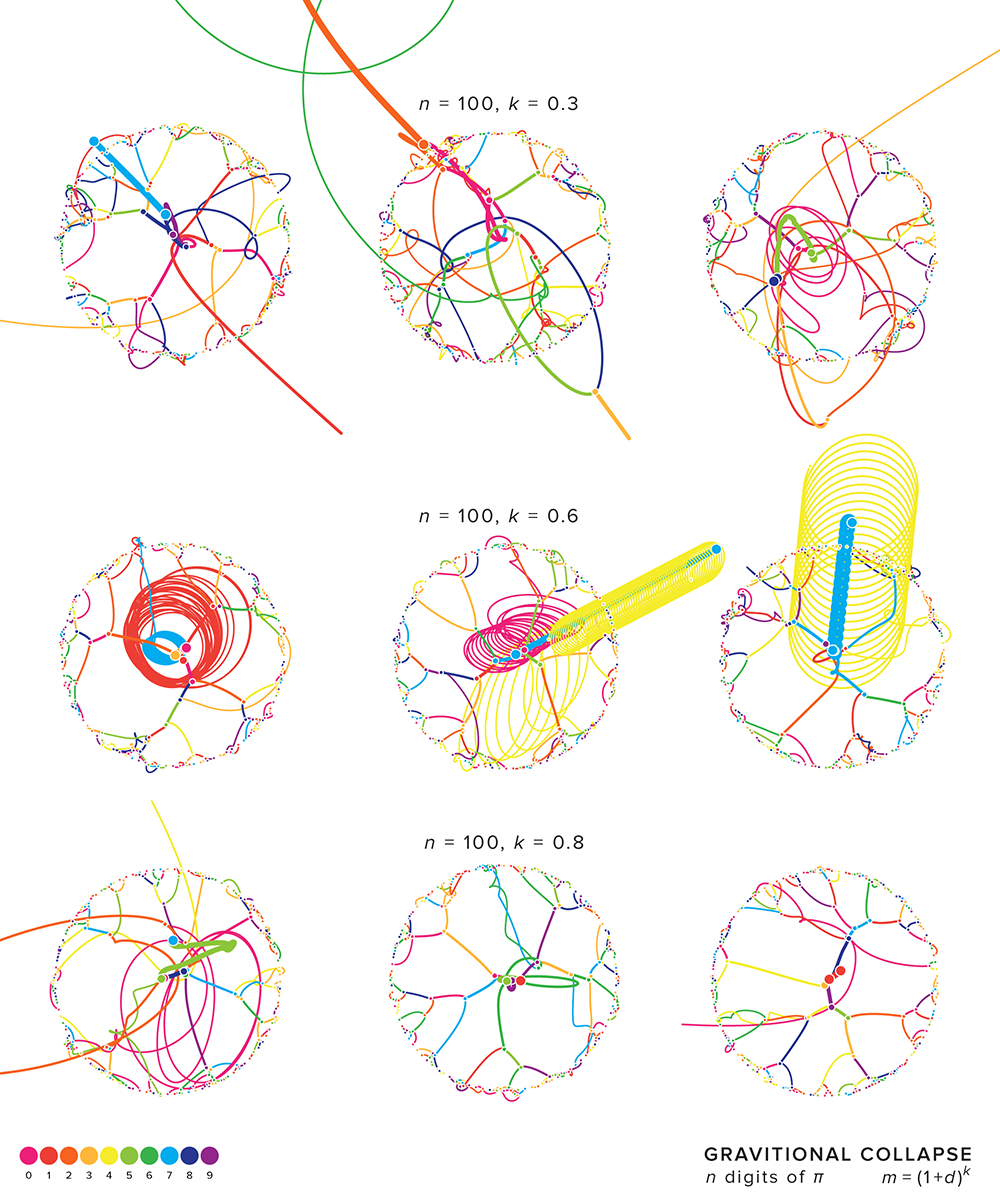
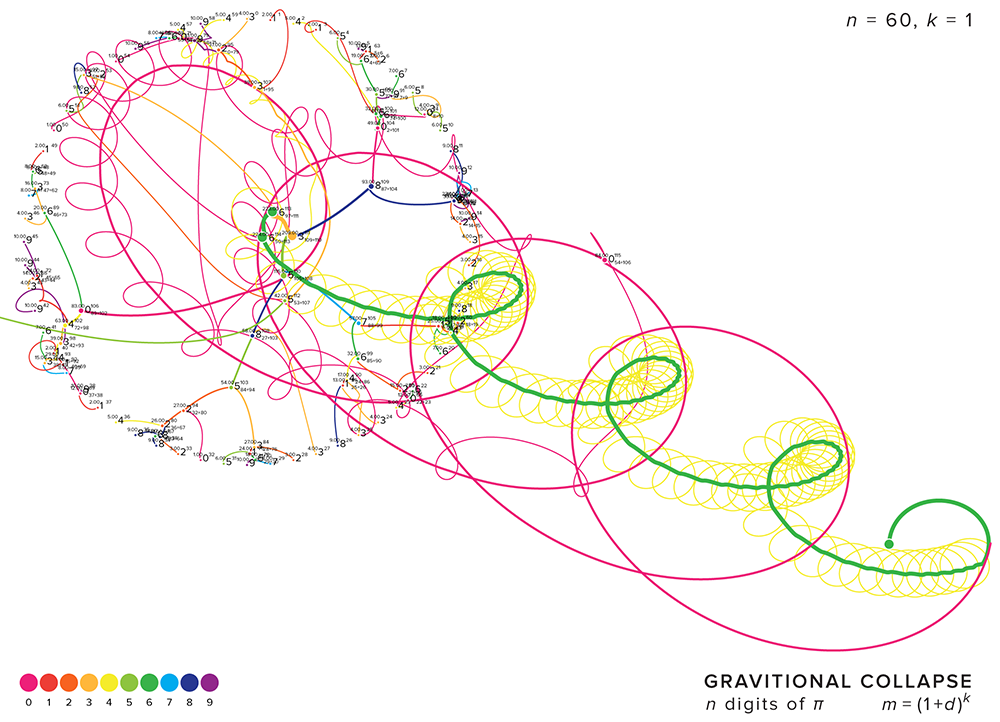
Below is a great example of how a stable orbital pattern of a pair of masses can be disrupted by the presence of another mass. You can see on the left that once the light red mass moves away from the orange/green pair, they settle into a stable pattern.
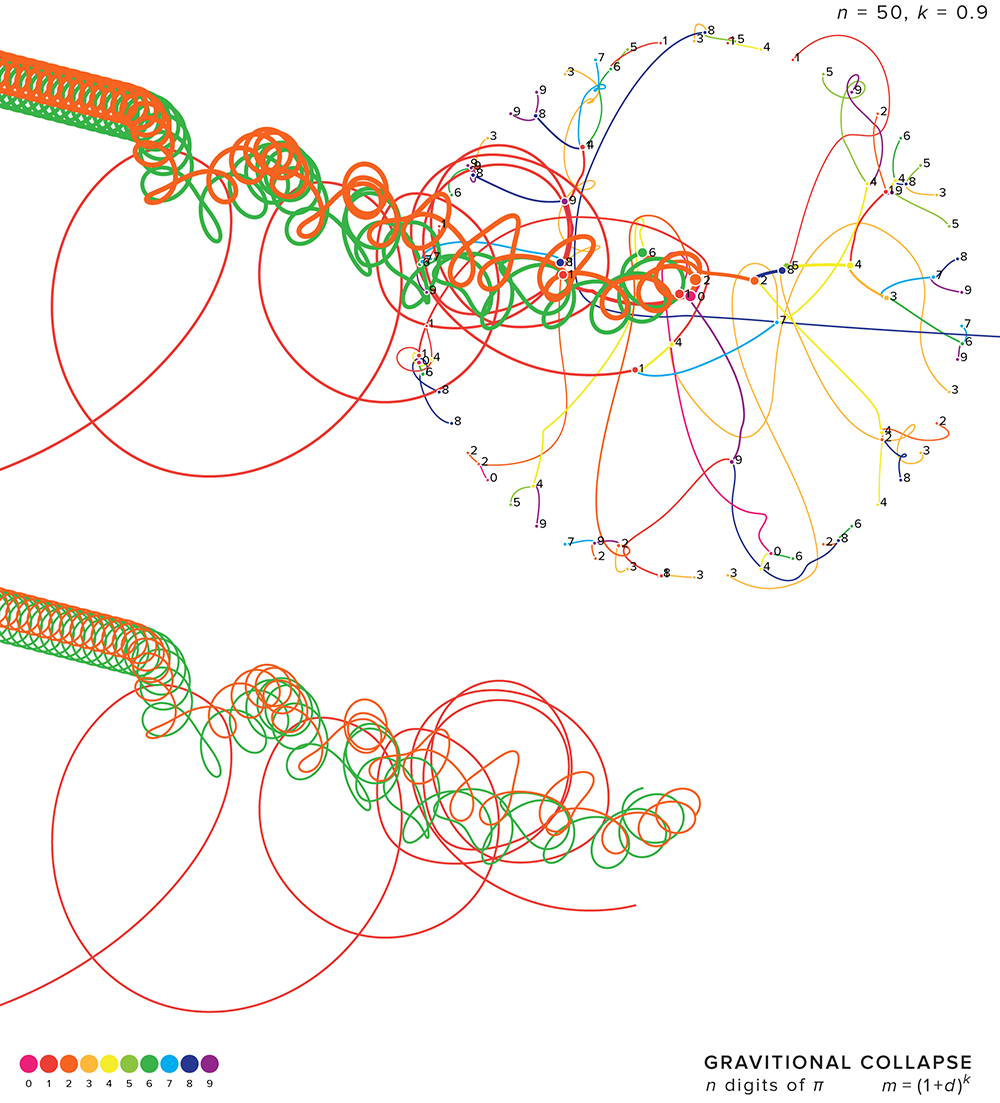
The figure below shows one of my favourite patterns. As the digits collide, three masses remain, which leave the system. They remain under each other's gravitational influence, but are moving too quickly to return to the canvas within the time of the simulation.
how the idea developed
interactive gravity simulator
Use this fun inteactive gravity simulator if you want to drop your own masses and watch them orbit.
Nasa to send our human genome discs to the Moon
We'd like to say a ‘cosmic hello’: mathematics, culture, palaeontology, art and science, and ... human genomes.



Comparing classifier performance with baselines
All animals are equal, but some animals are more equal than others. —George Orwell
This month, we will illustrate the importance of establishing a baseline performance level.
Baselines are typically generated independently for each dataset using very simple models. Their role is to set the minimum level of acceptable performance and help with comparing relative improvements in performance of other models.

Unfortunately, baselines are often overlooked and, in the presence of a class imbalance5, must be established with care.
Megahed, F.M, Chen, Y-J., Jones-Farmer, A., Rigdon, S.E., Krzywinski, M. & Altman, N. (2024) Points of significance: Comparing classifier performance with baselines. Nat. Methods 20.
Happy 2024 π Day—
sunflowers ho!
Celebrate π Day (March 14th) and dig into the digit garden. Let's grow something.

How Analyzing Cosmic Nothing Might Explain Everything
Huge empty areas of the universe called voids could help solve the greatest mysteries in the cosmos.
My graphic accompanying How Analyzing Cosmic Nothing Might Explain Everything in the January 2024 issue of Scientific American depicts the entire Universe in a two-page spread — full of nothing.

The graphic uses the latest data from SDSS 12 and is an update to my Superclusters and Voids poster.
Michael Lemonick (editor) explains on the graphic:
“Regions of relatively empty space called cosmic voids are everywhere in the universe, and scientists believe studying their size, shape and spread across the cosmos could help them understand dark matter, dark energy and other big mysteries.
To use voids in this way, astronomers must map these regions in detail—a project that is just beginning.
Shown here are voids discovered by the Sloan Digital Sky Survey (SDSS), along with a selection of 16 previously named voids. Scientists expect voids to be evenly distributed throughout space—the lack of voids in some regions on the globe simply reflects SDSS’s sky coverage.”
voids
Sofia Contarini, Alice Pisani, Nico Hamaus, Federico Marulli Lauro Moscardini & Marco Baldi (2023) Cosmological Constraints from the BOSS DR12 Void Size Function Astrophysical Journal 953:46.
Nico Hamaus, Alice Pisani, Jin-Ah Choi, Guilhem Lavaux, Benjamin D. Wandelt & Jochen Weller (2020) Journal of Cosmology and Astroparticle Physics 2020:023.
Sloan Digital Sky Survey Data Release 12
Alan MacRobert (Sky & Telescope), Paulina Rowicka/Martin Krzywinski (revisions & Microscopium)
Hoffleit & Warren Jr. (1991) The Bright Star Catalog, 5th Revised Edition (Preliminary Version).
H0 = 67.4 km/(Mpc·s), Ωm = 0.315, Ωv = 0.685. Planck collaboration Planck 2018 results. VI. Cosmological parameters (2018).
constellation figures
stars
cosmology
Error in predictor variables
It is the mark of an educated mind to rest satisfied with the degree of precision that the nature of the subject admits and not to seek exactness where only an approximation is possible. —Aristotle
In regression, the predictors are (typically) assumed to have known values that are measured without error.
Practically, however, predictors are often measured with error. This has a profound (but predictable) effect on the estimates of relationships among variables – the so-called “error in variables” problem.

Error in measuring the predictors is often ignored. In this column, we discuss when ignoring this error is harmless and when it can lead to large bias that can leads us to miss important effects.
Altman, N. & Krzywinski, M. (2024) Points of significance: Error in predictor variables. Nat. Methods 20.
Background reading
Altman, N. & Krzywinski, M. (2015) Points of significance: Simple linear regression. Nat. Methods 12:999–1000.
Lever, J., Krzywinski, M. & Altman, N. (2016) Points of significance: Logistic regression. Nat. Methods 13:541–542 (2016).
Das, K., Krzywinski, M. & Altman, N. (2019) Points of significance: Quantile regression. Nat. Methods 16:451–452.
Convolutional neural networks
Nature uses only the longest threads to weave her patterns, so that each small piece of her fabric reveals the organization of the entire tapestry. – Richard Feynman
Following up on our Neural network primer column, this month we explore a different kind of network architecture: a convolutional network.
The convolutional network replaces the hidden layer of a fully connected network (FCN) with one or more filters (a kind of neuron that looks at the input within a narrow window).
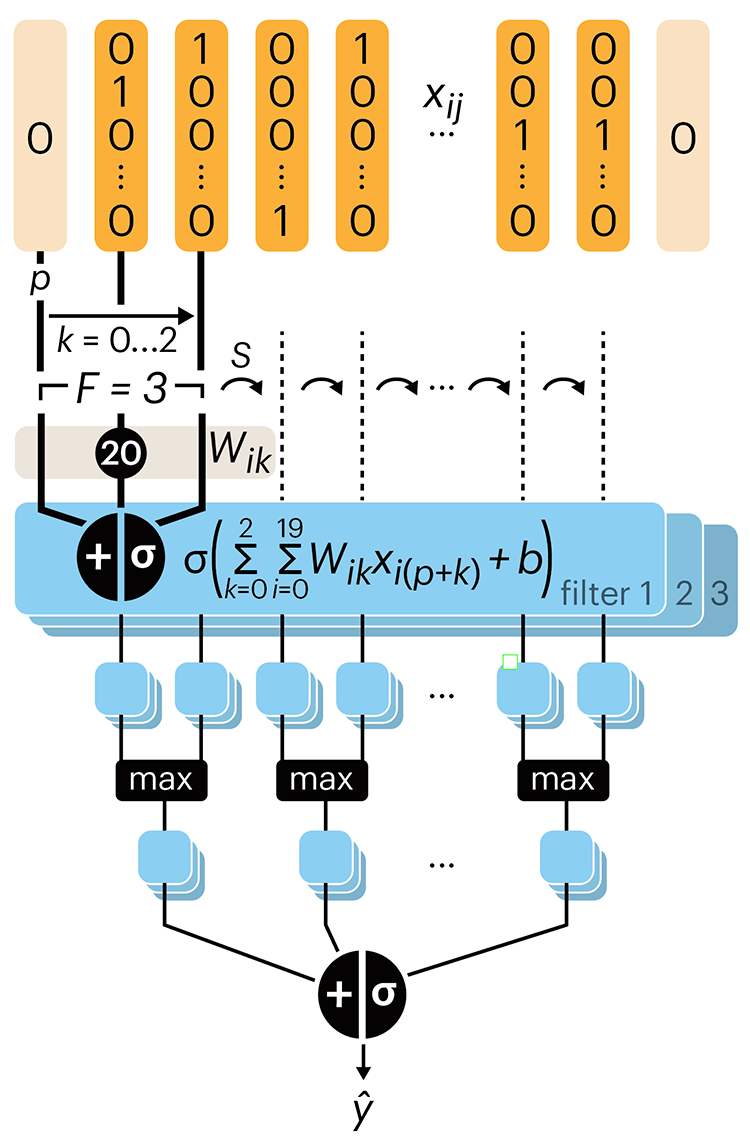
Even through convolutional networks have far fewer neurons that an FCN, they can perform substantially better for certain kinds of problems, such as sequence motif detection.
Derry, A., Krzywinski, M & Altman, N. (2023) Points of significance: Convolutional neural networks. Nature Methods 20:1269–1270.
Background reading
Derry, A., Krzywinski, M. & Altman, N. (2023) Points of significance: Neural network primer. Nature Methods 20:165–167.
Lever, J., Krzywinski, M. & Altman, N. (2016) Points of significance: Logistic regression. Nature Methods 13:541–542.