Hive Plots
Rational Network Visualization — Farewell to hairballs
Martin Krzywinski, Canada's Michael Smith Genome Sciences Center, Vancouver, BC
![Hive plots are useful, geeky and simple to implement. Go nuts. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](gfx/hiveplot-useful-geeky-simple.png)
the hive plot is a perceptually uniform and scalable linear layout visualization for network visual analytics
UNDERSTANDING NETWORK STRUCTURE WITH HIVE PLOTS.
(A) Normalized (top) and absolute (bottom) connectivity of E. coli gene regulatory network and Linux function call network (Yan et al.)
(B) Gene co-regulation networks in neuroblastoma samples.
(C) Network edges shown as ribbons creating circularly composited stacked bar plots (a periodic streamgraph).
(D) Syntenic network of three modern crucifer species to ancestral genome.
(E) Layered network correlation matrix. In each cell two layers u,v are depicted with u used to order axes and nodes while links for v are shown.
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/web-title-large.png)
![]()
We're interested in how you apply this network visualization method to your data set—let us know.
Published in BRIEFINGS IN BIOINFORMATICS
Krzywinski M, Birol I, Jones S, Marra M (2011). Hive Plots — Rational Approach to Visualizing Networks. Briefings in Bioinformatics (early access 9 December 2011, doi: 10.1093/bib/bbr069). (download citation)

Join the discussion (Rich Morin) about hive plots in d3.js (demo, github). New to hive plots? See this Useful d3.js + hive plot intro by Mike Bostock.
The hive plot is a rational visualization method for drawing networks. Nodes are mapped to and positioned on radially distributed linear axes — this mapping is based on network structural properties. Edges are drawn as curved links. Simple and interpretable.
The purpose of the hive plot is to establish a new baseline for visualization of large networks — a method that is both general and tunable and useful as a starting point in visually exploring network structure.
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](conference/ismb2011/netbiosig/hivepanel-human-dip-poster.png)
Hive plots give the reader a passing chance to quantitatively understand important aspects of a network's structure. Unlike hairballs (Network visualizations: how to tame the complexity Paweł Widera describes may layout options), hive plots are excellent at managing the visual complexity arising from large number of edges and exposing both trends and outlier patterns in network structure.
Multiple hive plots are presented together in a hive panel.
Several implementations of hive plots are available. A good way to get started is with our jhive Java implementation. Read the jhive documentation.
Network visualizations are notoriously difficult to interpret. Their canonical representation in a visual form has earned the moniker hairball, and you can probably guess why. If you are unfamiliar with the hairball, or doubt their prevalence in biological sicences, explore what is always a good source of network hairballs: study of yeast and systems biology.
![Network hairballs in the past, present and future. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](gfx/network-hairballs-past-present-future.png)
You can already guess that nothing with the name hairball can truly be useful. In general, they are not. These views are at best accidentally informative, and cannot be relied upon to consistently reveal meaningful patterns.
Interpreting hairballs is made difficult by several significant shortcomings
![A conventional network visualization - a hairball - someone make it stop. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](gfx/network-hairball-make-it-stop.png)
To rationally visualize networks, we introduce the hive plot. The hive plot is based on meaningful network properties, which can be selected to address a specific question.
Nodes are assigned to one of three (or more) axes, which may be divided into segments. Nodes are ordered on a segment based on properties such as connectivity, density, centrality or quantitative annotation (e.g. gene expression). The user is free to choose whatever rules fit their data and visualization requirements. Edges are drawn as Bezier curves, which can be annotated with color, thickness or label to communicate additional information.
Hive plots make it possible to assess network structure because they are founded on network properties, not on aesthetic layout. Visualizations of two networks are directly comparable. Importantly, hive plots are perceptually uniform — differences in hive plots are proportional to differences in underlying networks. This makes it possible to use hive plots to assess network similarity.
![A conventional network visualization - a hairball - someone make it stop. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](gfx/hiveplot-matrix-01.png)
![A conventional network visualization - a hairball - someone make it stop. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](gfx/hiveplot-matrix-02.png)
![A conventional network visualization - a hairball - someone make it stop. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](gfx/hiveplot-matrix-03.png)
![A conventional network visualization - a hairball - someone make it stop. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](gfx/hiveplot-matrix-04.png)
Any network can be represented as a hive plot (e.g. gene regulation, protein-protein interaction, internet traffic, user space in a social network, etc). When the axis segments are interpreted as sequence, the plot can show three-way alignment and conservation (e.g. Figure 3 in Fusobacterium nucleatum infection is prevalent in human colorectal carcinoma).
If connections are drawn as ribbons, the hive plot can demonstrate ratios between elements of normalized quantities (e.g. comparison of sizes of annotation categories in different genomes).
Conventional network visualization is unsuitable for visual analytics of large networks. So-called hairballs earn their moniker by becoming impenetrably complex as your network grows. They are least effective when visualization is most needed — for large networks.
![Conventional
network visualizations - hairballs - do not scale well. They become
unparasable for large networks. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-needs-visualization.png) To understand networks visually, we need to see their structure
directly, not by proxy of a layout algorithm based on aesthetics.
To understand networks visually, we need to see their structure
directly, not by proxy of a layout algorithm based on aesthetics.
Hairballs turn complex data into visualizations that are just as complex, or even more so. Hairballs can even seduce us to believe that they carry a high information value. But, just because they look complex does not mean that they can communicate complex information. Hairballs are the junk food of network visualization — they have very low nutritional value, leaving the user hungry.
In a hairball, data is subordinate to layout — node and edge positions and lengths depend as much on the layout algorithm (of which there are many), as on the data. The effect of layout rules is difficult to predict, making direct comparisons of these visualizations impossible. For example, imagine trying to compare two scatter plots in which the ordinality of the scales were altered (e.g. x = 1, 2, 3, ... in one and x = 3, 1, 2, ... in the other).
As a result, a great deal of detail about the structure of a network is irretrievably lost in a hairball and any emergent patterns may be either real (reflected in the data) or accidental (artefact of the layout). If you doubt that such artefacts can appear in the literature, consider the figure below from Rual JF, Venkatesan K, Hao T, et al. Towards a proteome-scale map of the human protein-protein inter- action network. Nature 2005;437(7062):1173–8. As indicated in the figure's legend, all notable features in the network visualization are artefacts of the layout algorithm.
![Figure 2b from Rual JF, Venkatesan K, Hao T, et al. Towards a proteome-scale map of the human protein-protein inter- action network. Nature 2005;437(7062):1173–8. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/rual-figure2b.png)
The central drawback of hairball-based visualization is that they cannot be tuned to address a user's specific questions. Implicit in the hairball approach is the assumption that all questions that the user wishes to answer are addressable by the layout algorithm. When this assumption is wrong (as it usually is), the user is left to construct another hairball, based on another layout algorithm, to attempt to answer the unanswered questions. Unfortunately, the set of questions answerable by a hairball is very difficult to determine — no such list exists because of the complex interplay of data and layout.
What can you tell from the hairball below? (e.g. graphminator, 18 mar 2010). I can tell this: hairballs have let us down.
![A conventional network visualization - a hairball. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-hairball-1.png)
![A conventional network visualization - a hairball. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-hairball-2.png)
![A conventional network visualization - a hairball. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-hairball-3.png)
![A conventional network visualization - a hairball. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-hairball-4.png)
![A conventional network visualization - a hairball. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-hairball-5.png)
![A conventional network visualization - a hairball. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-hairball-6.png)
I am not trying to persuade you to part with hairballs forever. Some hairball network visualizations are incredibly beautiful and the field of information graphics would not be the same without them.
![Beautiful network art is ... beautiful. Let's keep it. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-beautiful.png)
y.layout.router Class OrganicEdgeRouter / Large Graph Layout (LGL) / Today by Cada / Mapping the Human Disseaseome (Bloch/Corum NYT 2009)
The preparation of the kind of visualizations shown above is an effort of both labour and love. Specific layouts work for one network, but are not effective in general. There are exceptions, however. Some network families are ideally suited for a layout algorithm (e.g. y.layout.router in first panel above).
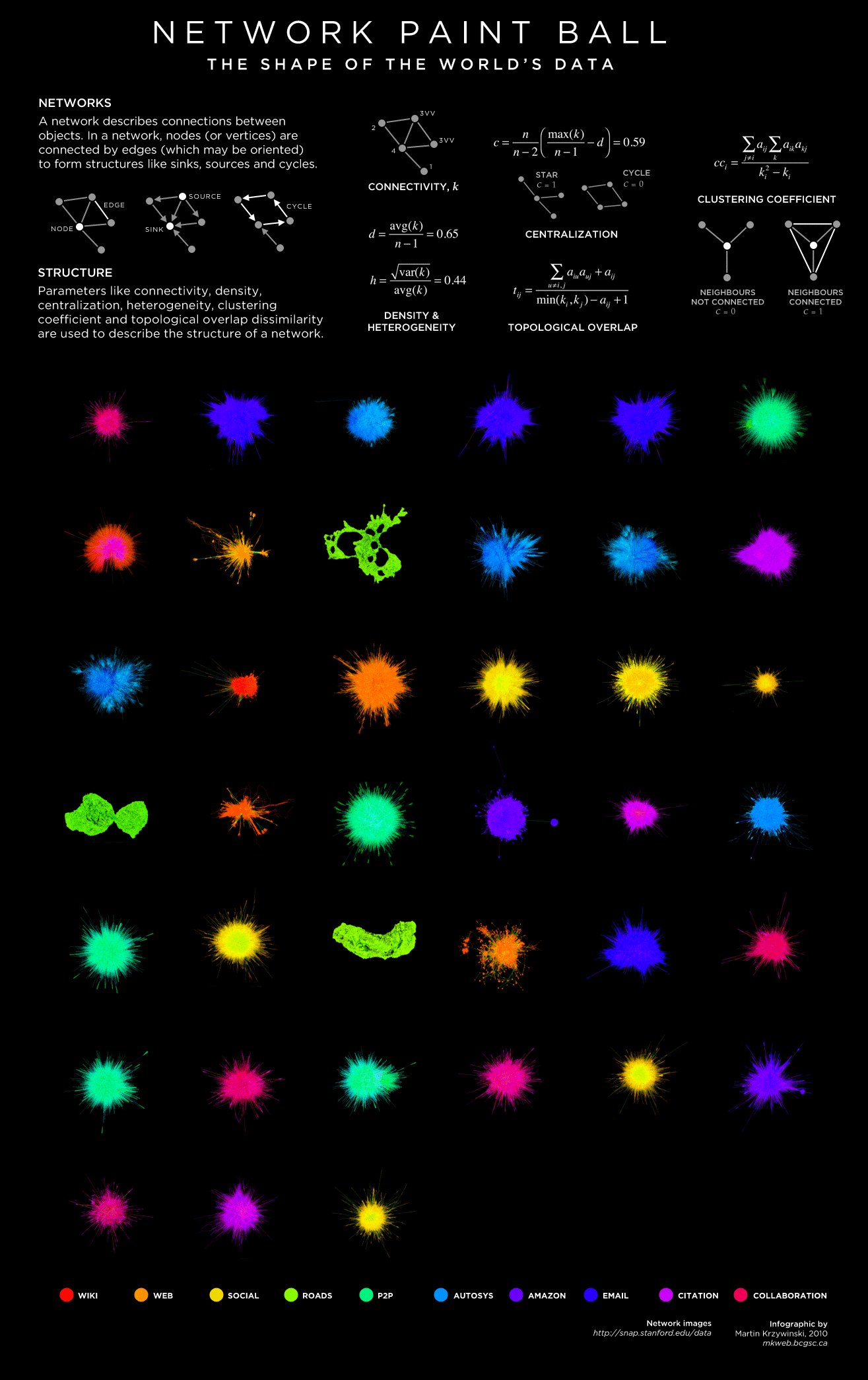
Before describing the hive plot method in detail, just to assure you that I love network art I've taken the hairballs of a variety of network communities and generated a "spatter profile".
Informative? Somewhat. Juicy? Absolutely.
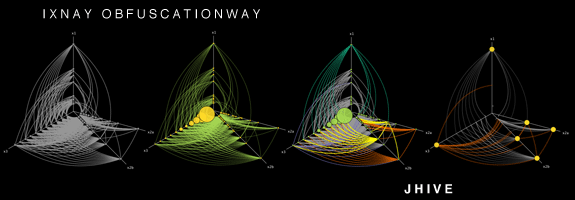
The hive plot attempt to address the shortcomings of the conventional hairball layout. Because hive plots can be tuned, they can identify meaningful structural components of a network. hive plots are ideal for detecting emerging patterns in your network's structure — the method shows you the entire network and your brain's pattern matching facilities do the rest.
The hive plot is itself founded on a layout algorithm. However, its output is not based on aesthetics but network structure. In this sense, the layout is rational — it depends on network features that you care about (e.g. connectivity).
In a hive plot, nodes are constrained to linear axes and edges are drawn as curves. Node-to-axis assignment and node-on-axis position are determined solely by network structure, node, edge annotation, or any other meaningful properties of the network. In other words, layout rules are defined by you based on properties that are meaningful to you. These rules form a mapping between structure and layout can be as simple or complex as you wish.
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-layout-01.png)
Importantly, there is no aesthetic magic sauce added to the layout. If the layout shows a pattern, you can be sure it is due to structure in the underlying data and not on the layout algorithm's interpretation of how the data should be shown.
The axis and node mapping is arbitrary, and this may sound very abstract at this point. To make things concrete, there are certain simple recipes that are extremely useful in most cases (see Krzywinski et al.).
Mapping to axis (A, in figure below), position (B) and color (C) can be a function of sink/source status (for tripartite networks, this axis categorization is natural), node degree, neighbour degree, centralization, density, heterogeneity, topological overlap (there are numerous properties to choose from), or node/edge annotation (e.g. a node could be associated with a classification, or an edge may have a weight).
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-mapping-01.png)
Interpretation of the linear visualization is easy (once you get the hang of it). Direct visual comparison of hive plots is possible — a valuable and distinguishing feature of hive plots. For example, consider the eight hairballs below — they are layouts of the same network. It is not possible to tell that this is in fact the same network.
![Different network layout algorithms produce different, and incomparable, visualizations. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/networklayouts.png)
If this causes you no concern, consider that simply rotating and/or flipping the same hairball can appear indistinguishable from changing the underlying data.
![Simply rotating and/or flipping a hairball can produce a result that appears different. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/networklayouts-invariance.png)
Consider a typical hairball. Now think of how you'd describe to someone the method used to create it. Chances are, even you don't know the full details of the layout algorithm. And even if you did, you could not necessarily relate how specific network structures would translate into output.
Even if you did describe how the hairball was created (you'd probably name the layout algorithm), it would be very likely that the description would not contain any phrases that relate to the structure of the network (which is, after all, what your audience is keen on).
On the other hand, it is easy to describe how a hive plot was created, and likewise easy for your audience to understand, because you can use terms relevant to the questions your visualization is designed to address. Instead of saying "I used a force-directed approach to place the nodes.", which does not help your audience relate to the network's structure, you can say "I put all the sink nodes on this axis and ordered them by absolute connectivity.", which is immediately meaningful.
Hive plots work equally well on both directed and undirected networks. In undirected networks, edges don't have a direction and therefore there is no distinction between sinks (nodes with in edges) and sources (nodes with out edges). In the example below, the node degree (number of edges) is used to map nodes to axes.
![Application of the linear layout for network visualization to an
undirected network (graph). [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-undirected-01.png)
A recent PNAS paper [1], Yan et al. compared the E. coli gene regulatory network with that of the function calls in the Linux kernel. As you can see, the hairballs of these networks reveal no structural information. Other that the Linux network is larger, the hairballs offer no other information.
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-hairball-02.png)
[1] Yan KK, Fang G, Bhardwaj N, Alexander RP, Gerstein M. 2010. Comparing genomes to computer operating systems in terms of the topology and evolution of their regulatory control networks. Proc Natl Acad Sci U S A 107(20): 9186-9191.
Yan et al. showed the networks with a parallel linear layout, shown below.

Nodes on the axes were not ordered. Network edges between the top and bottom layer cross the middle layer axis and complicate the view. For example, it is not immediately obvious that there is almost no communication in the first two layers of the E. coli network.
The linear layouts clearly demonstrate differences between these networks. For details about the linear layouts of these two networks, refer to slides in the general introduction.
Hover to pause, click to advance
![E. coli gene regulatory network visualized with the linear layout. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-ecoli.png)
![Linux kernel function call network visualized with the linear layout. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-linux.png)
Networks are complex data structures and it is rare that they can be effectively presented as a single image. The hive plot concept can be extended to hive panels — multiple and independent hive panel — a matrix of hive plots which independently communicate different structural properties of a network visual signatures of a network, each based on a different combination of structural properties to interrogate different aspects of network structure.
Hairballs cannot be used for this purpose because they are not sensitive to patterns in structural attributes, cannot be directly compared, and scale poorly.
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](conference/ismb2011/netbiosig/hivepanel-human-dip.png)
In the figure above, the core interactions of the human-human set from the database of interacting proteins (DIP) are depicted as a hive panel using the following properties: node clustering coefficient (cc), next-neighbor clustering coefficient (ccnn), node connectivity (deg), number of next-neighbors (nn), and page rank (pr). To demonstrate how the panel can focus attention, links to the most connected node are highlighted.
A single hive plot (deg vs cc) from hive panels of four organisms and a random network are shown below the human panel to demonstrate differences in connectivity and clustering coefficient. Shown also are organic layouts of the locale of the most connected node formed by its neighbors and next-nearest neighbors, the region of the network highlighted in the hive plots. Though it is not possible to confidently conclude anything from the organic layouts, the hive plots clearly communicate differences in a quantitative manner. For example, the most connected node in the human set (A) is more cliquey (large cc) than E. coli (C) and yeast (D) and is connected to nodes which themselves are uniformly cliquey (B). These and other patterns can be quickly identified within the panel.
Hive plots can be used to compare multiple networks. In this application, the nodes of each network are assigned to different axes and links connect nodes that are shared between the networks (or using some other node similarity criteria).
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/multi-axis-large.png)
Comparing four networks requires 6 axes, if the plot area is to be fully used.
Consider a network which contains multiple and independent layers of connections. How do the layers of connectivity relate?
![Application of the linear layout network visualization to layered networks. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-matrix-01.png)
By creating a hive plot in which the axis/position mapping is done using one layer, with edges of another layer drawn, correlation can be assessed visually.
![Application of hive plots (linear layout network visualization) to layered networks. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](img/hiveplot-matrix-02.png)
No.
Hive plots can be applied to data structures other than networks. The method requires that your data be mappable onto a set of pairwise relationships. For networks, this pairwise relationship is the edge between two nodes. In other circumstances, it can relate two spatial positions (where the axis corresponds to an object with a physical length scale) or two intervals (two axis segments are related, thereby creating a ratio comparison).
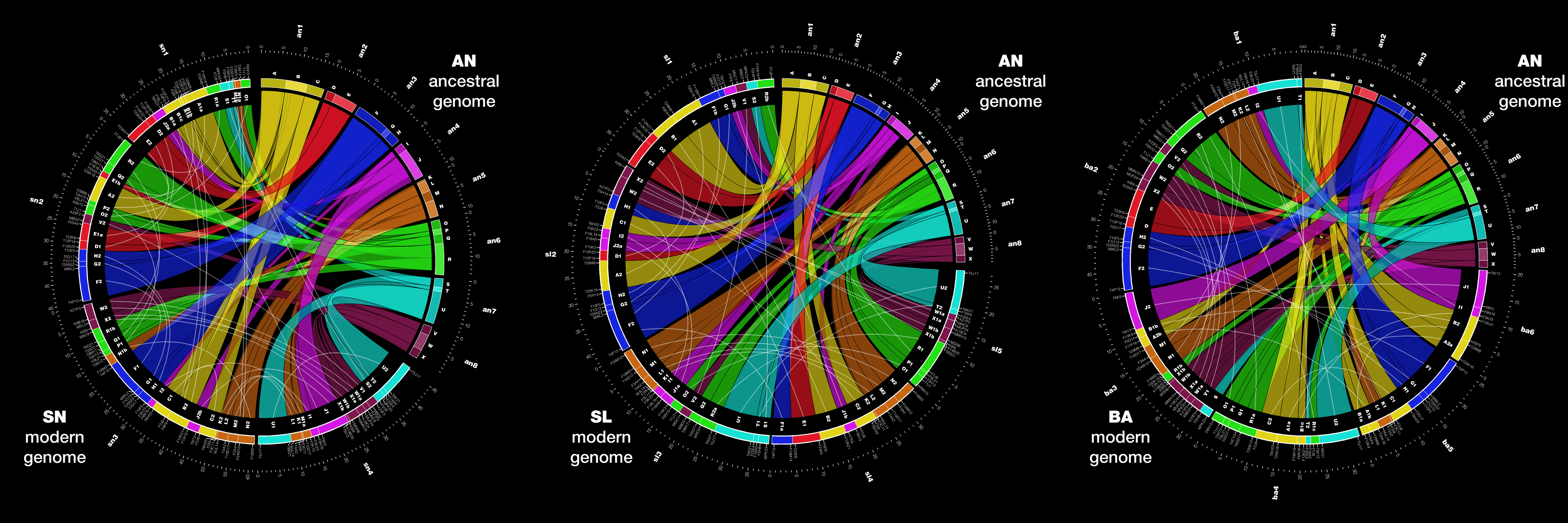
For example, three-way genome alignments are lucidly shown with hive plots as in the figure below, adapted from Figure 3 in Castellarin et al. Fusobacterium nucleatum infection is prevalent in human colorectal carcinoma Genome Research (2011).
Circos is a common method to show genome differences, synteny and alignments. For example, below are shown three comparisons of the ancestral genome of Arabidopsis thaliana with each of three modern genomes of the plan (SN, SL and BA) (Figure 3 from Mandakova T, Joly S, Krzywinski M, Mummenhoff K, Lysak MA (2010). Fast diploidization in close mesopolyploid relatives of Arabidopsis. The Plant cell 22: 2277-2290).
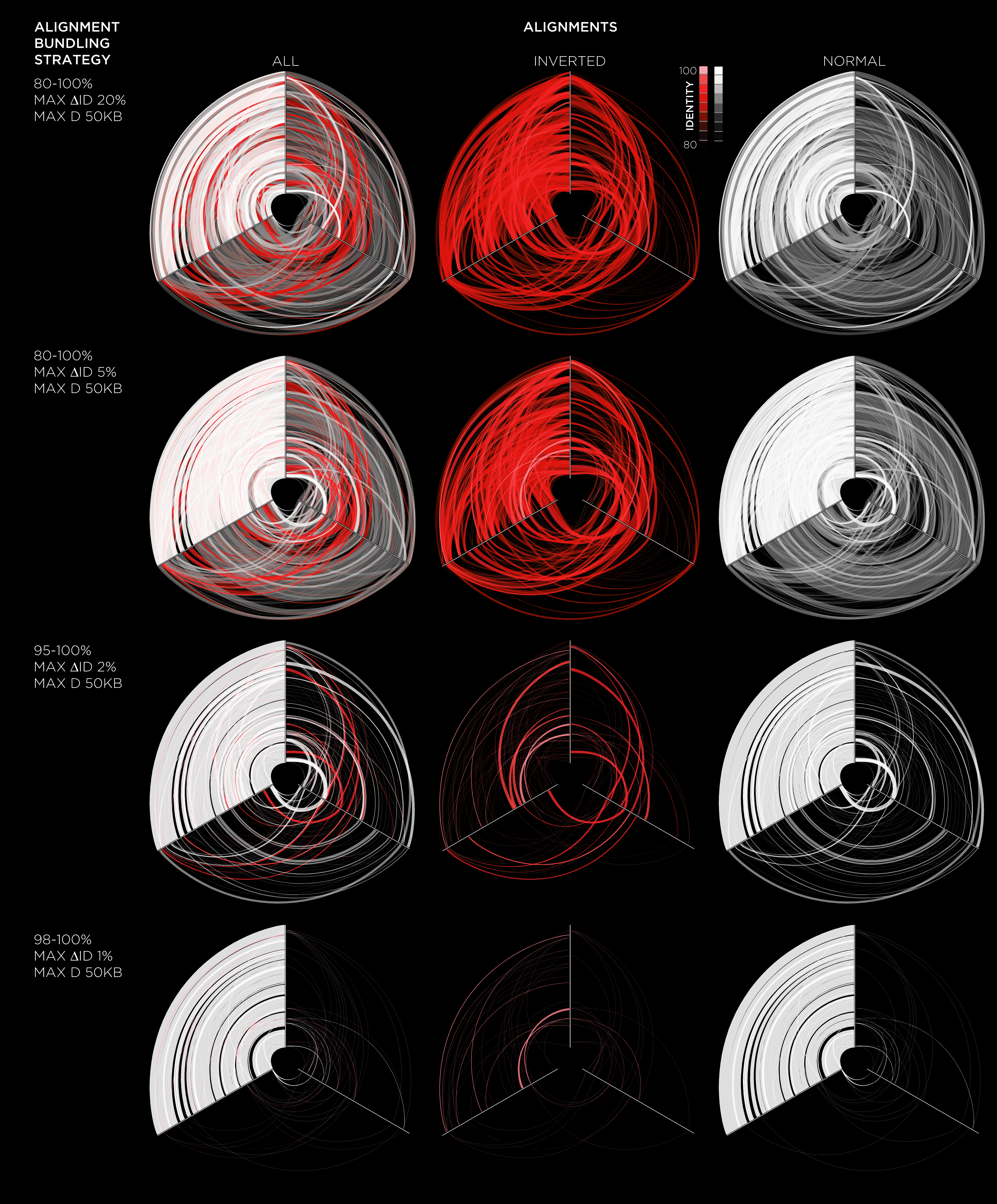
Hive plots make an excellent tool for showing three-way alignments. Below is a hive plot of all three alignments shown above. In this representation, positions on modern genomes that align to the same ancestral genome segment are connected.
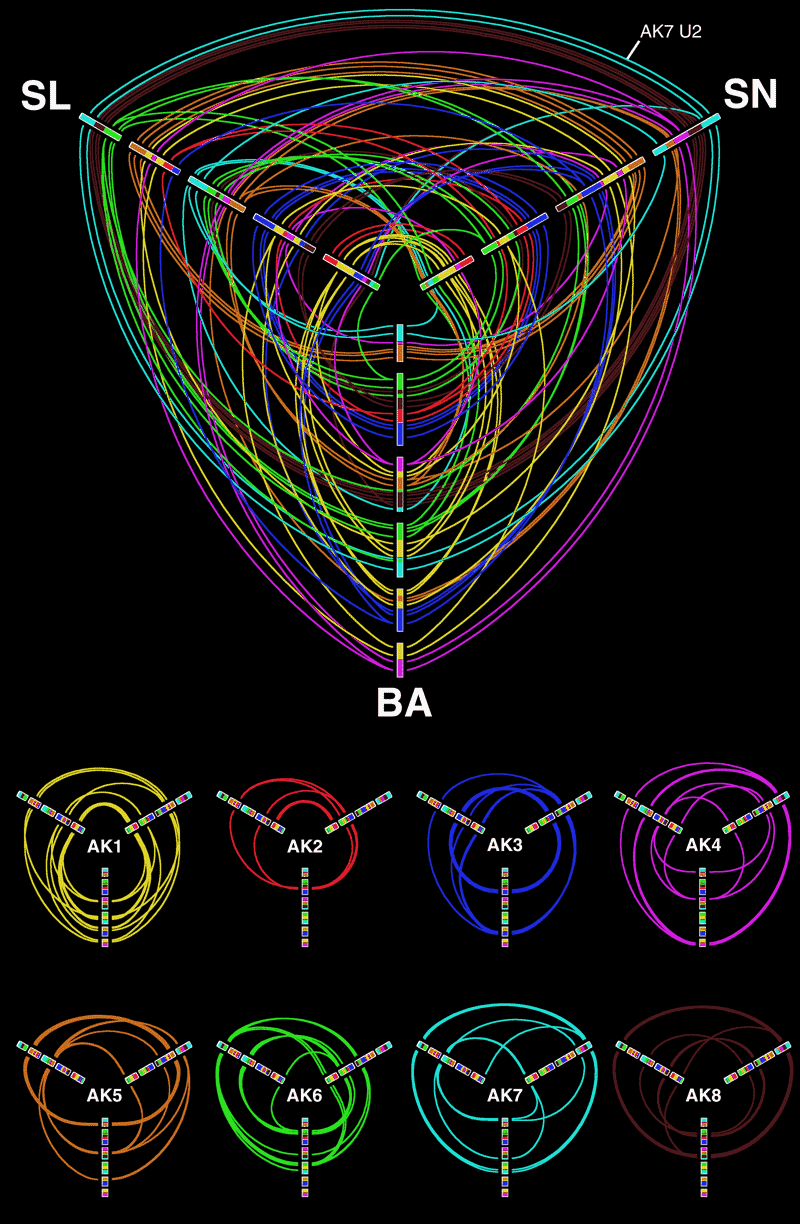
One variation of the hive plot is a circularly composited stacked bar plot, as shown below. In this example (hires, PDF), each of the three axes support two bar plots (on either side). Ribbons connect two intervals of the same category. For another example, see our VIZBI 2011 poster.
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ] - Assessing genome assembly quality with a hive plot, which compares reads, assembly and reference.](img/assembly-quality.png)
This hive plot provides a visual recipe for assessing the quality of a genomic assembly. An assembly is composed of reads (bottom axis), which are assembled into contigs (right axis). Independently, a reference assembly (left axis) may exist and act as a comparator. Among others, this hive plot answers the following questions:
The benefit of this stacked bar plot layout is that the circular layout is both periodic and has visual weight. This approach is similar to a parallel coordinate plot, except here the plot wraps around.
Multiple panels can be combined to display a very large number of ratios. Below are shown 3 x 3 x 3 (27) comparisons, each with 3 x 8 ratios, for a total of 648 ratios. By categorizing each ratio using a spectral color scheme, patterns can be quickly spotted and interpreted. The image below was created for the EMBO Journal 2011 cover contest.
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ] - Application of hive plots to visualizing ratios.](img/hiveplot-ratios-large.png)
A scalable, computationally fast, and straight-forward network visualization method that makes possible visual interpretation of network structure and evolution.
Martin Krzywinski
Canada's Michael Smith Genome Sciences Center / BC Cancer Research Center
A cross-platform interactive hive plot Java application.

jhive v0.2.7, 21 Jan 2014
HiveR is an R package for creating 2D and 3D hive plots. It was developed by Bryan Hanson (Department of Chemistry & Biochemistry, Depauw University) and is maintained on Github and CRAN.
Bryan A. Hanson (2011) HiveR: 2D and 3D Hive Plots for R. R package version 0.1-3, https://academic.depauw.edu/~hanson/HiveR/HiveR.html
Pyveplot by Rodrigo Garcia implements hive plots in Python.
Eric Ma (MIT) has a Python Hive Plot project, which is available on Python Notebook. He is also working on a Matplotlib version.
Brian Turner from the Wodak Lab at Toronto's Sick Kids Research Institute has created a web application to draw hive plots.
Hive plots generated for the publication in Briefings in Bioinformatics were generated with our hive plot Perl prototype.
linnet v0.02, Dec 2011

To run, you'll need perl and a few modules. The code is actually quite small and the bulk of the 25+ Mb distribution is sample images. Start by going through example graphs in
examples/networkEach directory contains README files that explain role and structure of file contained therein.
Use the Google group for questions about installation, configuration, features and applications.
Mike Bostock's d3.js javascript visualization framework can be used to create hive plots.
Introduction to Hive Plots v2
Introduction to Hive Plots v1
Hive Plots — Genome Informatics 2010
Don't make hairballs. We don't need another CSI spinoff.
Visualizations for the CSI badges were taken from SNAP.
![[ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ] - VIZBI 2011 Poster](conference/vizbi2011/poster/krzywinski-hiveplot-poster.png)
VIZBI 2011
16-19 Mar 2011
5 Nov 2010
8 Oct 2010
17 Sep 2010
Dogma








![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![ISBM 2011 Network Bioiology SIG Poster. [ Hive Plots - Rational Network Visualization - A Simple, Informative and Pretty Linear Layout for Network Analytics - Martin Krzywinski ]](conference/ismb2011/netbiosig/hivepanel-human-dip-poster-small.png)
{kind=link}