Without an after or a when.
•
• can you hear the rain?
• more quotes







very clickable
π day
·
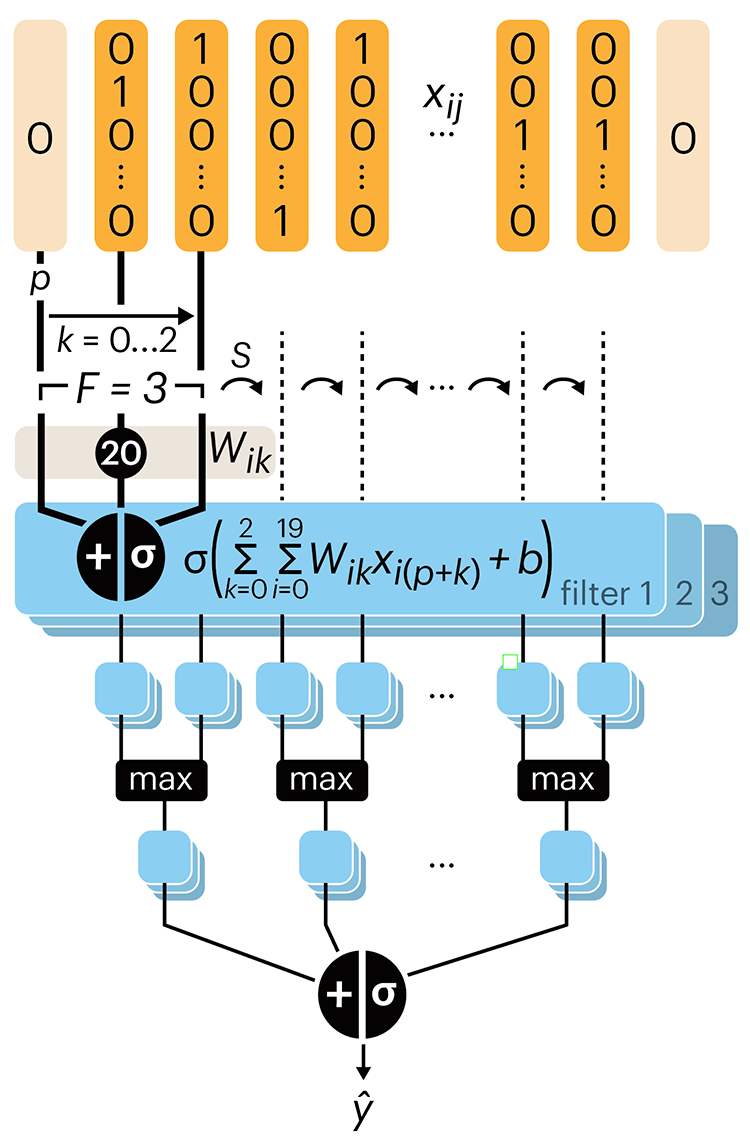
ASCII
·
choices
·
clocks
·
color
·
constellations
NEW
·
covers
NEW
·
deadly genomes
NEW
·
debates
·
emotions
·
famous rat
·
gigapixel skies
NEW
·
hitchens
·
keyboards
·
languages
·
LOTRO
·
photography
·
questions
·
quotes
·
road trips
·
rockets
·
satire
·
spam poetry
·
time
·
tripsum
·
type
·
unwords
·
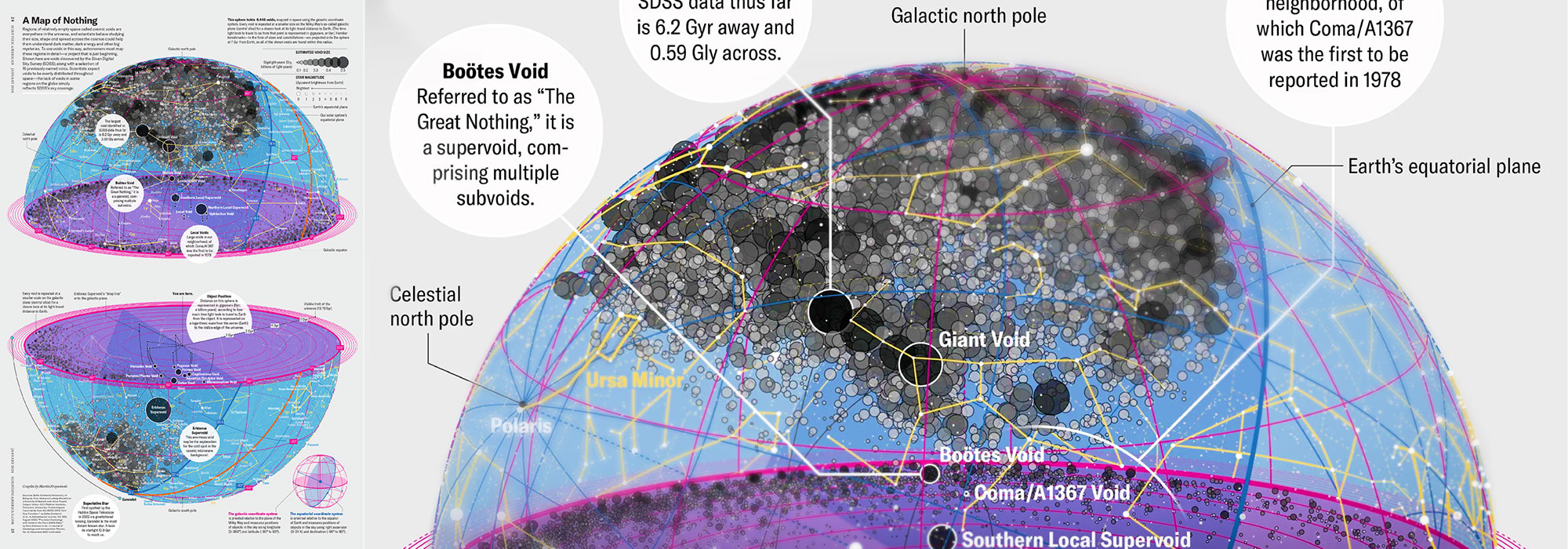
voids
·
words
·
writing
·
zaomm

BCGSC.CA 10TH ANNIV AdrianALLY JianghongAN RuthAPPANAH LukeARMSTRONG JenniferASANO MehranATAEE TimothyAU-YEUNG JosieAUDET HeatherAXAM LanceBAILEY MirunaBALA AdrianaBANUELOS LorenaBARCLAY MishaBILENKY InancBIROL IanBOSDET KarlaBRETHERICK AngelaBROOKS-WILSON MabelBROWN-JOHN RichardBRUSKIEWICH YaronBUTTERFIELD RebeccaCARLSEN MauroCASTELLARIN TimotheeCEZARD SusannaCHAN SimonCHAN JustinCHAN ClintonCHAN SteveCHAND Chi-DanCHANG AnitaCHARTERS DeborahCHEN GraceCHENG DeanCHENG DorothyCHEUNG RodneyCHIN SuganthiCHITTARANJAN ReadmanCHIU StephanieCHO GinaCHOE RobertCHRISP AndyCHU EricCHUAH ElizabethCHUN StellaCHUN LouiseCLARKE AmandaCLARKE RobinCOOPE RichardCORBETT MonicaCORNEAN AdrianCORTES LuluCRISOSTOMO KattyCRUZ CletusD'SOUZA AllenDELANEY AthenaDENG MerindaDENG LindsayDEVORKIN NoreenDHALLA RodDOCKING LisaDREOLINI AdrienneDROBNIES MadaleneEARP AmyENGLISH NoushinFARNOUD AnthonyFEJES CynthiaFERGUSON MatthewFIELD StephaneFLIBOTTE DanFORNIKA DougFREEMAN FrancisFRENO MarilynGILLESPIE BeckyGILLESPIE NatalieGLAVAS SharonGORSKI RodrigoGOYA MalachiGRIFFITH ObiGRIFFITH RanGUIN ImanHAJIRASOULIHA JuliusHALASCHEK-WIENER AdamHALL AdrienneHANNIGAN JenniferHARDIE RubayetHASAN AnHE SeanHENDERSON UljanaHESSE MartinHIRST CarrieHIRST RobertHOLT DanielHORSPOOL ClaireHOU JayneHUNTER TakaakiICHU ShaunJACKMAN CarrieJANG RozminJANOO-GILANI KelseyJEFFERSON JupiterJIANG ChaoyangJIN LindseyJOHNSON JoanneJOHNSON StevenJONES BaljitKAMOH MiraKARIA KatayoonKASAIAN UsmanKHAN JieunKIM HeatherKIRK MartinKRZYWINSKI LetticiaKWONG DarwinLAHUE AnthonyLE StephenLEACH DarleneLEE Hyun-WuLEE AmyLEUNG DidiLEUNG YvonneLI IreneLI SaLI NancyLIAO YuSiLIU KevinMA DianaMAH NawarMALHIS MarcoMARRA CoreyMATSUO RinaMAWJI NasrinMAWJI LorraineMAY MichaelMAYO HelenMCDONALD StephanieMCINNIS HeatherMCMURTRIE Carri-LynMEAD MariaMENDEZ-LAGO SimonHaileMERHU DianeMILLER MichelleMOKSA RichardMOORE AnnieMORADIAN RyanMORIN GreggMORIN OlenaMOROZOVA AndyMUNGALL KarenMUNGALL SarahMUNRO JillMWENIFUMBO Jae-KyungMYUNG RichardNEWSOME JoanNG CydneyNIELSEN KarenNOVIK DianaPALMQUIST PawanPANDOH JohnsonPANG IrenePELOSO LinhPHAN ReneePICHE Anna-LiisaPRABHU TrevorPUGH JennyQIAN LisaRAEBURN RitaRAHARJO MaziarRAHMANI JianhuaREN GordonROBERTSON RobynROSCOE RouzbehROSHANRAVAN SharonRUSCHKOWSKI DanneSA MarianneSADAR MurwanSALAME RolandSANTOS JacquieSCHEIN JohannaSCHUETZ TesaSEVERSON ArashSHAFIEI HeesunSHIN SanjitSINGH RanjitSINGH JaredSLOBODAN DuaneSMAILUS JillianSMITH RichardSOBEL SoranaMORRISSY GregSTAZYK DominikSTOLL CeceliaSURAGH Wing-KaSZE IsabellaTAI AngelaTAM BonnyTAM TeresaTAM SamuelTAN MichelleTANG GregTAYLOR KevinTEAGUE NinaTHIESSEN KenTHORNE TinaTHORNE AncaTOMESCU EvaTRINH ArmelleTROUSSARD MirandaTSAI KaneTSE RichardVARHOL SusanWAGNER GangWANG JeanWANG ReneWARREN DenilWICKRAMA MiriamWILLIAMS GaryWILSON TinaWONG JohnWONG KenWRIGHT JacksonWU NatasjaWYE AlexanderYAKOVENKO GeorgeYANG KevinYANG RunyingYANG DenizYORUKOGLU ThomasZENG XuekuiZHANG YongjunZHAO MiZHOU 261109mk